Threat Intel’s ‘History of…’ series will look at the origins and evolution of notable developments in cyber security.
What
exactly is cloud computing? This is something that, no doubt, most
people have wondered in recent times, as more and more of the services
we use have migrated to the semi-mythical “cloud”.
One dictionary definition of cloud computing defines it as: “Internet-based computing in which large groups of remote
servers are networked so as to allow sharing of data-processing tasks,
centralized data storage, and online access to computer services or
resources.” Users no longer need vast local services to access storage
or carry out certain tasks, they can do it all “in the cloud”, which
essentially means over the internet.
If we go back to the very beginning, we can trace cloud computing’s origins all the way back to the 1950s,
and the concept of time-sharing. At that time, computers were both huge
and hugely expensive, so not every company could afford to have one. To
tackle this, users would “time-share” a computer. Basically, they would
rent the right to use the computer’s computational power, and share the
cost of running it. In a lot of ways, that remains the basic concept of
cloud computing today.
In
the 1970s, the creation of “virtual machines” took the time-share model
to a new level. This development allowed multiple computing
environments to be housed in one physical environment. This was a key
development that made it possible for the cloud computing we know today
to develop.
Professor
Ramnath Chellappa is often credited with being the person who coined
the term “cloud computing” in its modern context, at a lecture he
delivered in 1997. He defined it then as
a “computing paradigm where the boundaries of computing will be
determined by economic rationale rather than technical limits alone.”
However, some months before this, in 1996, a business plan created by a group of technologists at Compaq
also used the term when discussing the “evolution” of computing. So,
while the source of the expression might be in dispute, it is clear that
the modern “cloud” was something that was being seriously thought about
by those in the IT industry in the mid ’90s — 20 years ago.
Modern developments
In
2006, Amazon launched Amazon Web Services (AWS), which provided
services such as computing and storage in the cloud. Back then, you
could rent computer power or storage from Amazon by the hour. Nowadays,
you can rent more than 70 services,
including analytics, software and mobile services. Its S3 storage
service holds reams of data and services millions of requests every
second. Amazon Web Services is used by more than one million customers
in 190 countries. Massive companies including Netflix and AOL don’t
have their own data centers but exclusively use AWS. Its projected
revenue for 2017 was $18 billion.
While
the other major tech players, such as Microsoft Azure, did subsequently
launch their own cloud offerings to compete with AWS, it dominates the
cloud infrastructure market; according to recent reports,
at the end of 2017 it held a 62 percent market share of the public
cloud business, with Microsoft Azure holding 20 percent, and Google 12
percent. While AWS is still way ahead of its rivals in this space, it is
interesting to note that its market share did drop since the previous
year, while both Microsoft and Google’s market share grew.
While
AWS dominates in the enterprise space, when it comes to consumers, they
are probably most familiar with services like Dropbox, iCloud and
Google Drive, which they use to store back-ups of photos, documents, and
more. The increased use by people of mobile devices with smaller
storage capacities increased the need for cloud-based storage among
consumers. While they may lack understanding about what exactly the
cloud is, it is likely that most consumers are using at least one
cloud-based service. The cloud has allowed for the growth of the mobile
economy, in many ways, allowing for the development of apps that may not
have been possible in the absence of a cloud infrastructure.
In organizations, the numbers using cloud services is even larger. The Symantec ISTR 2017
showed that the average enterprise has 928 cloud apps in use, though
many businesses don’t realize that their employees are actually using so
many cloud services.
The growth of mobile devices led to an inevitable growth in cloud usage by consumers
Security concerns
However,
while there are many advantages to cloud computing, and many reasons
why companies and individuals use cloud services, it does present some
security concerns. One of the appeals of information stored on the cloud
is that it can be accessed remotely, however, if inadequate security
protocols are in place, this is also one of its weaknesses. There have
been many stories in the news about Amazon S3 buckets being left on the web unsecured
and revealing personal information about people. However, as it seems
unlikely that cloud computing is going anywhere, the answer to these
kinds of issues is more likely to be improving people’s cyber security
practices to ensure they protect data stored online with strong
passwords and other forms of authentication, such as two-factor and
encryption.
The
adoption of cloud was almost inevitable in our hyper-connected world.
The need for computing power and storage simply became too expensive and
too much for many businesses and individuals to tackle, meaning they
needed to farm out these tasks to cloud services. As the move to mobile
continually escalates, and as the Internet of Things (IoT) continues to
grow as a sector, cloud computing is set to continue its growth.
It may have started out as a marketing term, but cloud computing is an important reality in today’s IT world.
Check out the Security Response blog and follow Threat Intel on Twitter to keep up-to-date with the latest happenings in the world of threat intelligence and cybersecurity.
Like
this story? Recommend it by hitting the heart button so others on
Medium see it, and follow Threat Intel on Medium for more great content.
Note:
this article is an introduction to video streaming in JavaScript and is
mostly targeted to web developers. A large part of the examples here
make use of HTML and modern JavaScript (ES6). If you’re not sufficiently familiar with them, you may find it difficult to follow through, especially the code example. Sorry in advance for that.
The need for a native video API
From the early to late 2000s, video playback on the web mostly relied on the flash plugin.
Screen warning that the user should install the flash plugin, at the place of a video
This
was because at the time, there was no other mean to stream video on a
browser. As a user, you had the choice between either installing
third-party plugins like flash or silverlight, or not being able to play
any video at all.
To fill that hole, the WHATWG began to work on a new version of the HTML standard including, between other things, video and audio playback natively (read here: without any plugin). This trend was even more accelerated following Apple stance on flash for its products. This standard became what is now known as HTML5.
The HTML5 Logo. HTML5 would be changing the way video are streamed on web pages
Thus HTML5 brought, between other things, the <video> tag to the web.
This new tag allows you to link to a video directly from the HTML, much like a <img> tag would do for an image. This
is cool and all but from a media website’s perspective, using a simple
img-like tag does not seem sufficient to replace our good ol' flash:
we might want to switch between multiple video qualities on-the-fly (like YouTube does) to avoid buffering issues
live streaming is another use case which looks really difficult to implement that way
and
what about updating the audio language of the content based on user
preferences while the content is streaming, like Netflix does?
Thankfully, all of those points can be answered natively on most browsers, thanks to what the HTML5 specification brought. This article will detail how today’s web does it.
The video tag
As
said in the previous chapter, linking to a video in a page is pretty
straightforward in HTML5. You just add a video tag in your page, with
few attributes.
For example, you can just write:
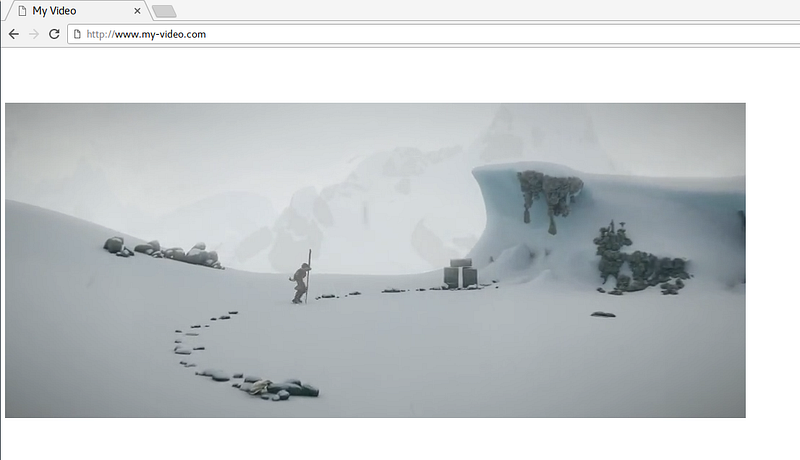
This HTML will allow your page to stream some_video.mp4 directly on any browser that supports the corresponding codecs (and HTML5, of course). Here is what it looks like:
Simple page corresponding to the previous HTML code
This video tag also provides various APIs to e.g. play, pause, seek or change the speed at which the video plays. Those APIs are directly accessible through JavaScript:
However,
most videos we see on the web today display much more complex behaviors
than what this could allow. For example, switching between video
qualities and live streaming would be unnecessarily difficult there.
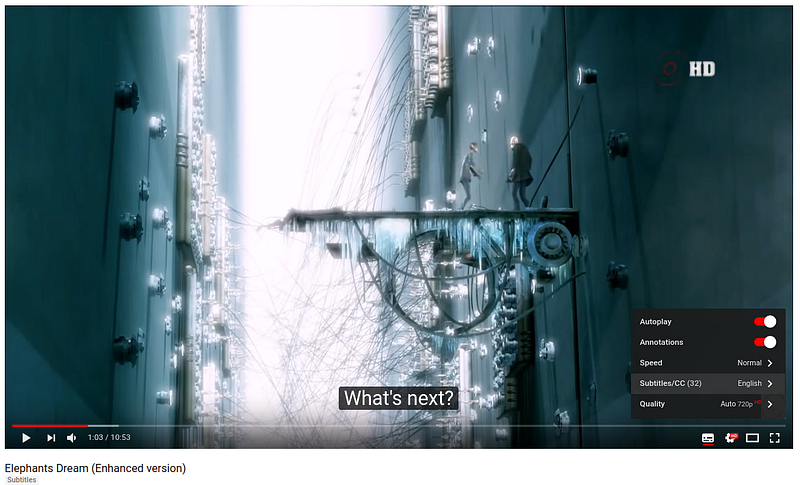
YouTube displays some more complex usecases: quality switches subtitles a tightly controlled progressive-download of the video…
All those websites actually do still use the video tag. But instead of simply setting a video file in the src attribute, they make use of much more powerful web APIs, the Media Source Extensions.
The Media Source Extensions
The
“Media Source Extensions” (more often shortened to just “MSE”) is a
specification from the W3C that most browsers implement today. It was
created to allow those complex media use cases directly with HTML and
JavaScript.
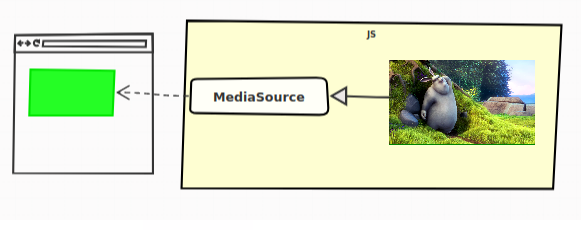
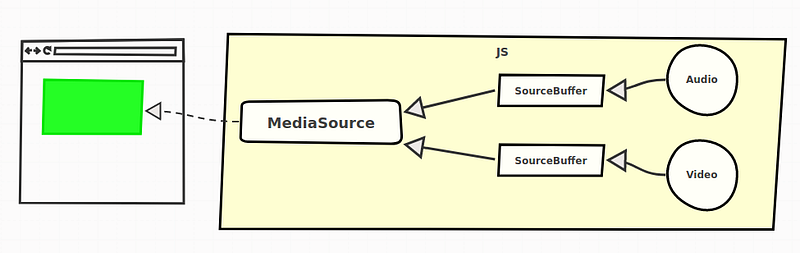
Those “extensions” add the MediaSource
object to JavaScript. As its name suggests, this will be the source of
the video, or put more simply, this is the object representing our
video’s data.
The video is here “pushed” to the MediaSource, which provides it to the web page
As written in the previous chapter, we still use the HTML5 video tag. Perhaps even more surprisingly, we still use its src attribute. Only this time, we're not adding a link to the video, we're adding a link to the MediaSource object.
You
might be confused by this last sentence. We’re not talking about an URL
here, we’re talking about an abstract concept from the JavaScript
language, how can it be possible to refer to it as an URL on a video
tag, which is defined in the HTML?
To allow this kind of use cases the W3C defined the URL.createObjectURL
static method. This API allows to create an URL, which will actually
refer not to a resource available online, but directly to a JavaScript
object created on the client.
This is thus how a MediaSource is attached to a video tag:
And that’s it! Now you know how the streaming platforms play videos on the Web! … Just kidding. So now we have the MediaSource, but what are we supposed to do with it?
The MSE specification doesn’t stop here. It also defines another concept, the SourceBuffers.
The Source Buffers
The video is not actually directly “pushed” into the MediaSource for playback, SourceBuffers are used for that.
A MediaSource contains one or multiple instances of those. Each being associated to a type of content.
To stay simple, let’s just say that we have only three possible types:
audio
video
both audio and video
In reality, a “type” is defined by its MIME type, which may also include information about the media codec(s) used
SourceBuffers
are all linked to a single MediaSource and each will be used to add our
video’s data to the HTML5 video tag directly in JavaScript.
As
an example, a frequent use case is to have two source buffers on our
MediaSource: one for the video data, and the other for the audio:
Relations between the video tag, the MediaSource, the SourceBuffers and the actual data
Separating
video and audio allows to also manage them separately on the
server-side. Doing so leads to several advantages as we will see later.
This is how it works:
And voila! We’re now able to manually add video and audio data dynamically to our video tag.
It’s
now time to write about the audio and video data itself. In the
previous example, you might have noticed that the audio and video data
where in the mp4 format. “mp4” is a container format,
it contains the concerned media data but also multiple metadata
describing for example the start time and duration of the media
contained in it.
The MSE specification does not dictate which format must be understood by the browser. For video data, the two most commons are mp4 and webm
files. The former is pretty well-known by now, the latter is sponsored
by Google and based on the perhaps more known matroska format (“.mkv”
files).
Both are well-supported in most browsers.
Media Segments
Still, many questions are left unanswered here:
Do
we have to wait for the whole content to be downloaded, to be able to
push it to a SourceBuffer (and therefore to be able to play it)?
How do we switch between multiple qualities or languages?
How to even play live contents as the media isn’t yet finished?
In
the example from the previous chapter, we had one file representing the
whole audio and one file representing the whole video. This can be
enough for really simple use cases, but not sufficient if you want to go
into the complexities offered by most streaming websites (switching
languages, qualities, playing live contents etc.).
What
actually happens in the more advanced video players, is that video and
audio data are splitted into multiple “segments”. These segments can
come in various sizes, but they often represent between 2 to 10 seconds
of content.
Artistic depiction of segments in a media file
All
those video/audio segments then form the complete video/audio content.
Those “chunks” of data add a whole new level of flexibility to our
previous example: instead of pushing the whole content at once, we can
just push progressively multiple segments.
Here is a simplifiedexample:
This
means that we also have those multiple segments on server-side. From
the previous example, our server contains at least the following files:
Note: The audio or video files might not truly be segmented on the server-side, the Range
HTTP header might be used instead by the client to obtain those files
segmented (or really, the server might do whatever it wants with your
request to give you back segments). However these cases are implementation details. We will here always consider that we have segments on the server-side.
All
of this means that we thankfully do not have to wait for the whole
audio or video content to be downloaded to begin playback. We often just
need the first segment of each.
Of
course, most players do not do this logic by hand for each video and
audio segments like we did here, but they follow the same idea:
downloading sequentially segments and pushing them into the source
buffer.
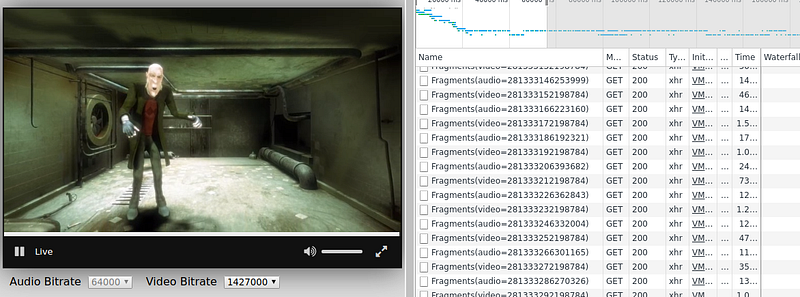
A funny way to see this logic happen in real life
can be to open the network monitor on Firefox/Chrome/Edge (on linux or
windows type “Ctrl+Shift+i” and go to the “Network” tab, on Mac it
should be Cmd+Alt+i then “Network”) and then launching a video in your
favorite streaming website. You should see various video and audio segments being downloaded at a quick pace:
Screenshot of the Chrome Network tab on the Rx-Player’s demo page
By
the way, you might have noticed that our segments are just pushed into
the source buffers without indicating WHERE, in terms of position in
time, it should be pushed. The segments’ containers do in fact
define, between other things, the time where they should be put in the
whole media. This way, we do not have to synchronize it at hand in
JavaScript.
Adaptive Streaming
Many
video players have an “auto quality” feature, where the quality is
automatically chosen depending on the user’s network and processing
capabilities.
This is a central concern of a web player called adaptive streaming.
A web player will then automatically choose the right segments to download as the network or CPU conditions change.
This is entirely done in JavaScript. For audio segments, it could for example look like that:
As
you can see, we have no problem putting together segments of different
qualities, everything is transparent on the JavaScript-side here. In any
case, the container files contain enough information to allow this
process to run smoothly.
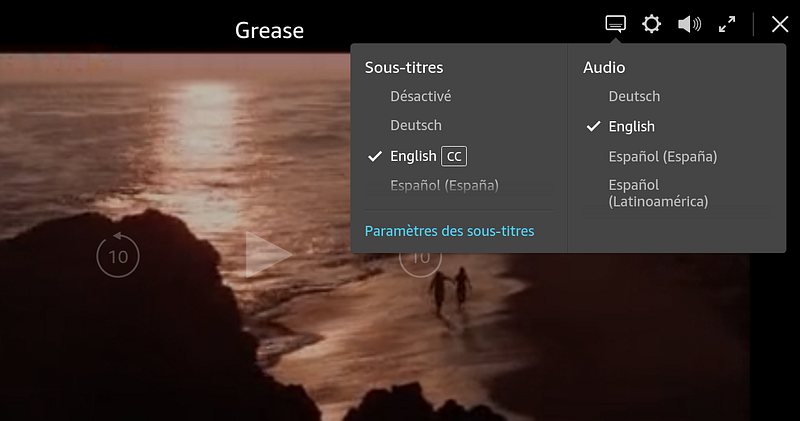
Switching between languages
On
more complex web video players, such as those on Netflix, Amazon Prime
Video or MyCanal, it’s also possible to switch between multiple audio
languages depending on the user settings.
Example of language options in Amazon Prime Video
Now that you know what you know, the way this feature is done should seem pretty simple to you.
Like for adaptive streaming we also have a multitude of segments on the server-side:
And our client would have to manage both languages and network conditions instead:
As you can see, there’s now a lot of way the same content can be defined.
This
uncovers another advantage separated video and audio segments have over
whole files. With the latter, we would have to combine every
possibilities on the server-side, which might take a lot more space:
Here we have more files, with a lot of redundancy (the exact same video data is included in multiple files).
This
is as you can see highly inefficient on the server-side. But it is also
a disadvantage on the client-side, as switching the audio language
might lead you to also re-download the video with it (which has a high
cost in bandwidth).
Live Contents
We didn’t talk about live streaming yet.
Live
streaming on the web is becoming very common (twitch.tv, YouTube live
streams…) and is again greatly simplified by the fact that our video and
audio files are segmented.
Screenshot taken from twitch.tv, which specializes on video game live streaming
To
explain how it basically works in the simplest way, let’s consider a
YouTube channel which had just begun streaming 4 seconds ago.
If
our segments are 2 seconds long, we should already have two audio
segments and two video segments generated on YouTube’s server:
Two representing the content from 0 seconds to 2 seconds (1 audio + 1 video)
Two representing it from 2 seconds to 4 seconds (again 1 audio + 1 video)
./audio/
├── segment0s.mp4
└── segment2s.mp4
./video/
├── segment0s.mp4
└── segment2s.mp4
At 5 seconds, we didn’t have time to generate the next segment yet, so for now, the server has the exact same content available.
After 6 seconds, a new segment can be generated, we now have:
This
is pretty logical on the server-side, live contents are actually not
really continuous, they are segmented like the non-live ones but
segments continue to appear progressively as time evolves.
Now how can we know from JS what segments are available at a certain point in time on the server?
We might just use a clock on the client, and infer as time goes when new segments are becoming available on the server-side. We would follow the “segmentX.mp4" naming scheme, and we would increment the “X” from the last downloaded one each time (segment0.mp4, then, 2 seconds later, Segment1.mp4 etc.).
In
many cases however, this could become too imprecise: media segments may
have variable durations, the server might have latencies when
generating them, it might want to delete segments which are too old to
save space… As a client, you want to request the latest segments as
soon as they are available while still avoiding requesting them too soon
when they are not yet generated (which would lead to a 404 HTTP error).
This problem is usually resolved by using a transport protocol (also sometimes called Streaming Media Protocol).
Transport Protocols
Explaining
in depth the different transport protocol may be too verbose for this
article. Let’s just say that most of those have the same core concept:
the Manifest.
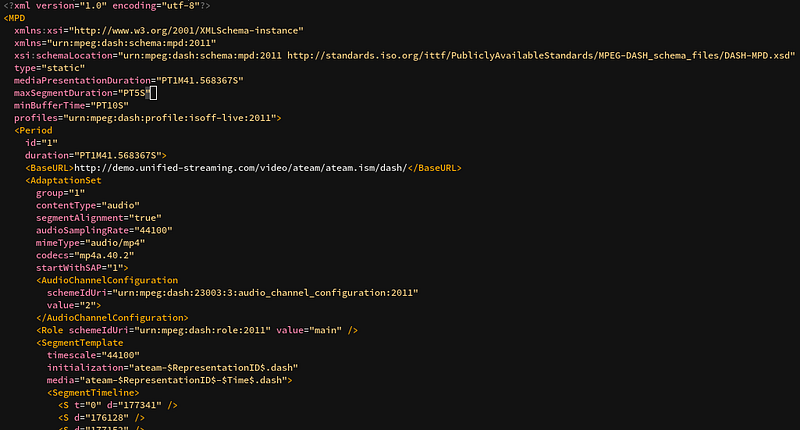
A Manifest is a file describing which segments are available on the server.
Example of a DASH Manifest, based on XML
With it, you can describe most things we learn in this article:
Which audio languages the content is available in and where they are on the server (as in, “at which URL”)
The different audio and video qualities available
And of course, what segments are available, in the context of live streaming
The most common transport protocols used in a web context are:
DASH used
by YouTube, Netflix or Amazon Prime Video (and many others). DASH’
manifest is called the Media Presentation Description (or MPD) and is at
its base XML. The DASH specification has a great flexibility which
allow MPDs to support most use cases (audio description, parental
controls) and to be codec-agnostic.
HLS Developped
by Apple, used by DailyMotion, Twitch.tv and many others. The HLS
manifest is called the playlist and is in the m3u8 format (which are m3u
playlist files, encoded in UTF-8).
Smooth Streaming Developped
by Microsoft, used by multiple Microsoft products and MyCanal. In
Smooth Streaming, manifests are called… Manifests and are XML-based.
In the real — web — world
As you can see, the core concepts behind videos on the web lays on media segments being pushed dynamically in JavaScript.
This behavior becomes quickly pretty complex, as there’s a lot of features a video player has to support:
it has to download and parse some sort of manifest file
it has to guess the current network conditions
it needs to register user preferences (for example, the preferred languages)
it has to know which segment to download depending on at least the two previous points
it
has to manage a segment pipeline to download sequentially the right
segments at the right time (downloading every segments at the same time
would be inefficient: you need the earliest one sooner than the next
one)
it has also to deal with subtitles, often entirely managed in JS
Some video players also manage a thumbnails track, which you can often see when hovering the progress bar
Many services also require DRM management
and many other things…
Still, at their core, complex web-compatible video players are all based on MediaSource and SourceBuffers.
Their web players all make use of MediaSources and SourceBuffers at their core
That’s why those tasks are usually performed by libraries, which do just that. More
often than not, those libraries do not even define a User Interface.
They mostly provide a rich APIs, take the Manifest and various
preferences as arguments, and push the right segment at the right time
in the right source buffers.
This
allows a greater modularization and flexibility when designing media
websites and web application, which, by essence, will be complex
front-ends.
Open-source web video players
There
are many web video players available today doing pretty much
what this article explains. Here are various open-source examples:
rx-player:
Configurable player for both DASH and Smooth Streaming contents.
Written in TypeScript — Shameless self-plug as I’m one of the dev.
dash.js:
Play DASH contents, support a wide range of DASH features. Written by
the DASH Industry Forum, a consortium promoting inter-operability
guidelines for the DASH transport protocol.
hls.js: well-reputed HLS player. Used in production by multiple big names like Dailymotion, Canal+, Adult Swim, Twitter, VK and more.
shaka-player: DASH and HLS player. Maintained by Google.
By the way, Canal+ is hiring ! If working with that sort of stuff interests you, take a look at http://www.vousmeritezcanalplus.com/ (⚠️ French website).
Last night I was struggling to fall asleep. So I started to reflect on a documentary I had seen. It was dedicated to Nikola Tesla, the visionary inventor who was obsessed with electrical energy at the turn of the 19th and 20th centuries.
The story that made me reflect is the famous “currents war” (a movie version with Benedict Cumberbatch has just been released). Thomas Alva Edison
argued that direct current was the ideal solution to “electrify” the
world, and invested on it large sums. Tesla, who worked a few months for
Edison, was instead convinced that alternating current was to be used.
I do not go into technical explanations. Let’s just say that Tesla, allying with Edison’s rival, the industrialist George Westinghouse,
won it. Today we use alternating current (AC), but then transform it
into continuous (DC) when we need to power our digital devices (or any
other battery-powered object).
The
question I asked myself was: if there were no Westinghouse and Tesla,
would we have direct current distribution networks today?
Most likely not, because the advantages of AC distribution would still have emerged, and even rather soon.
More generally, the question is: are there unavoidable technologies?
Are there any alternative technological paths?
In
the only case study available, that of human civilization, some
discoveries and inventions, and the order with which they were made,
seems to be obligatory: fire-> metals-> agriculture-> city->
wheel-> earthenware for example.
But
also hunter-gatherer societies could have invented the wheel: it would
have been very convenient for them, there was no reason not to have the
idea and they had the ability to build it. Perhaps some tribes did so,
using it for generations before memory was lost.
A sculpture of Göbekli Tepe -By Teomancimit — Yükləyənin öz işi, CC BY-SA 3.0
Scholars
think that to get to the monumental buildings, cities and civilizations
we must go through the agriculture: the production surplus is able to
support a large number of people and to give birth to social classes, as
nobles and priests dispensed from manual work but able to “commission”
great works.
The extraordinary discovery of the Göbekli Tepe
temple — dating from around 9,500 BC — has however questioned the need
for the transition to an urban society with social differentiations to
create such buildings.
Another
example. Sophisticated mechanisms such as those of clocks began to
spread in the early Middle Ages, with the first specimens placed in
church bell towers.
Why
did not the Greeks or the Romans, so skilled in the practical arts,
come to develop similar mechanisms? In fact, after the discovery of the Antikythera mechanism,
a sophisticated astronomical calculator, we have seen how the
capabilities (for example to have minimum tolerances) and the techniques
to build high precision instruments existed. Probably social, economic
and commercial structures more than technological limits did not allow
to have Roman pendulum clocks. In the same way, having a lot of low-cost
labor, the slaves, did not stimulate the invention of steam engines, if
not some rare and simple system used for “special effects” in the
temples.
With
regard to the innovations of the last 120 years, it is important to
underline, alas, the crucial importance of the two world wars,
especially the second, for the acceleration of technological
development; we only think of rocketry and computer science, born in
that period, and electronics developed shortly after (and there was the
Cold War …).
If there had not been World War II, what technologies would be surrounded by our daily life?
Probably
we will be at the level of the 60s / 70s, with mainframes, first
satellites in orbit, color televisions but with cathode ray tubes, first
commercial jet planes, just in time production chains etc.
Perhaps
an analog Internet would have developed, thanks to unpredictable
developments in the amateur radio network hybridized to systems such as
fax and video / audio cassettes.
Difficult to establish the timelines, life cycles of individual technologies, their interconnections and interdependencies.
In
a complex system such as that of human society, small variations in the
initial conditions can generate great changes in the trajectories and
directions of the space of innovations.
As a last example we think of the web. Sir Timothy John Berners-Lee created it while working at CERN in 1990.
The
web (or a similar one) could have been developed at least 10 years
before, in one of the American universities already inter-connected with
a telematic network.
This
would have meant that the portals of the first web would have appeared
at the end of the 80s, the web 2.0 around 1994, the social networks
would have been established around 1997 and today … we can not know it.
Also because there would have been a longer interval to have the mobile
web, since in any case the evolution of mobile telephony would have
followed its course as in our timeline. Or not?
Every
New Year brings around a buzz of excitement in the world of technology.
And with 2017, being a year full of innovations and surprises, the
expectations for 2018 are set to the highest standards as well.
Technology trends keep evolving and changing over time. They determine
the way we live, work and move ahead towards the future. Of all the
technology trends that come into the market, only a few manage to set a
milestone. Keeping that in mind, here is our list of the 5 best
technology trends to watch out for in 2018.
5. Bigger and Clearer TVs
pricekart.com
With
the concept of 4K televisions just sinking in, companies are already
here with the next best resolution for TVs. Companies like LG, Samsung
and Sony have already come up with their concept for the 8K TV. LG
displayed its first ‘88-inch 8K OLED TV’ that comes with 33 million
pixels at the CES 2018. And while that wasn’t enough, the company also showcased a ‘65-inch Rollable TV’.
The
Rollable TV will feature 4K resolution and can be rolled in a tube form
and carried around in a box, making it a portable TV. Similarly,
Samsung launched the first ever modular TV called “The Wall”. It is a
146-inch modular TV that can be resized to any size that the user
requires. All these innovations make a trend to definitely watch out for
this year.
4. Wireless Charging All Around
It
is not the first time wireless charging has been spoken about or
adapted to charge devices. But this trend is certainly going to be seen
everywhere, on most devices this year. Wireless charging works by
placing the smartphone on a Qi-compatible charging mat. The mat plugs
into a wire from an outlet to supply power.
However,
this year might also see over-the-air wireless charging. This will work
by delivering power to the devices over the air. Power can be
transferred to devices that are at least two or more feet away and can
reach up to 80 feet. Over-the-air wireless charging could be used for
charging devices like smartphones, smart speakers, smart watches and
wireless keyboards.
3. AR Over VR
We have seen Virtual Reality (VR) being one of the most trending technologies of the previous year. Virtual reality headsets
help us immerse into a 3D environment that does not really exist. But
this looks like the year of Augmented Reality (AR). The entire concept
of AR revolves around delivering immersive experiences without having to
shut yourself from the real world.
Augmented
Reality shows a better version of the real world by overlaying virtual
information on top of it. Using computer-generated images over the
user’s real-world view to enhance everything the user feels, sees and
hears, is what augmented reality is all about. Companies like Kinmo,
Kodak, Carl Zeiss, Sony and even Netflix will be introducing AR to the
technology market this year. This technology trend could come of great
assistance in everyday life.
2. All-in-one Voice Assistants
Voice control is going to dominate 2018. Voice assistants determine the way we interact with computers. Google Assistant, Samsung Bixby
and Amazon’s Alexa have already made their place by doing things that
are asked of them. Things like playing the music, getting updates on the
weather, and suggesting places nearby based on your current location,
are things that we have already seen.
But
voice assistants in 2018 will be able to carry out more than just the
basic commands. For instance, information about your daily schedule,
cooking recipes and other commands for your voice assistant to carry out
will be added. Additionally, not just smartphones and speakers, these
assistants will also be integrated inside televisions, headphones and
even cars.
1. Ultra Thin Laptops
lg.com
Technology evolved from desktops to laptops for features like the portability and weight. And if that wasn’t sufficient, ultra-thin laptops
are here to make their place. Acer recently unveiled the world thinnest
laptop, the Acer Swift 7. The laptop is as thin as 8.9mm and sports a
built-in fingerprint sensor. Likewise, even Dell launched its new
version of the Dell XPS 13 laptop which is as thin as 11.66 mm. This
makes it pretty evident that the upcoming laptops for this year are
going to compete to be slim among all the other features.
Hardik Gandhi is Master of Computer science,blogger,developer,SEO provider,Motivator and writes a Gujarati and Programming books and Advicer of career and all type of guidance.