To
anyone working in technology (or, really, anyone on the Internet), the
term “AI” is everywhere. Artificial intelligence — technically, machine learning — is finding application in virtually every industry on the planet, from medicine and finance to entertainment and law enforcement.
As the Internet of Things (IoT) continues to expand, and the potential
for blockchain becomes more widely realized, ML growth will occur
through these areas as well.
While
current technical constraints limit these models from reaching “general
intelligence” capability, organizations continue to push the bounds of
ML’s domain-specific applications, such as image recognition and natural
language processing. Modern computing power (GPUs in particular) has contributed greatly to these recent developments — which is why it’s also worth noting that quantum computing will exponentialize this progress over the next several years.
Alongside
enormous growth in this space, however, has been increased criticism;
from conflating AI with machine learning to relying on those very
buzzwords to attract large investments, many “innovators” in this space have drawn criticism from technologists
as to the legitimacy of their contributions. Thankfully, there’s plenty
of room — and, by extension, overlooked profit — for innovation with
ML’s security and privacy challenges.
Reverse-Engineering
Machine learning models, much like any piece of software, are prone to theft and subsequent reverse-engineering. In late 2016, researchers
at Cornell Tech, the Swiss Institute EPFL, and the University of North
Carolina reverse-engineered a sophisticated Amazon AI by analyzing
its responses to only a few thousand queries; their clone replicated the
original model’s output with nearly perfect accuracy. The process is
not difficult to execute, and once completed, hackers will have
effectively “copied” the entire machine learning algorithm — which its
creators presumably spent generously to develop.
The risk this poses will only continue to grow. Inaddition
to the potentially massive financial costs of intellectual property
theft, this vulnerability also poses threats to national
security — especially as governments pour billions of dollars into autonomous weapon research.
Not
only is this attack a threat to the network itself (i.e. consider this
against a self-driving car), but it’s also a threat to companies who
outsource their AI development and risk contractors putting their own
“backdoors” into the system. Jaime Blasco, Chief Scientist at security
company AlienVault, points out that this risk will only increase as the world depends more and more on machine learning. What would happen, for instance, if these flaws persisted in military systems? Law enforcement cameras? Surgical robots?
Training Data Privacy
Protecting the training data put into machine learning models is yet another area that needs innovation. Currently, hackers can reverse-engineer user data out of machine learning models
with relative ease. Since the bulk of a model’s training data is often
personally identifiable information —e.g. with medicine and
finance — this means anyone from an organized crime group to a business
competitor can reap economic reward from such attacks.
Further,
as organizations seek personal data for ML research, their clients
might want to contribute to the work (e.g. improving cancer detection)
without compromising their privacy (e.g. providing an excess of PII that
just sits in a database). These two interests currently seem at
odds — but they also aren’t receiving much
focus, so we shouldn’t see this opposition as inherent. Smart redesign
could easily mitigate these problems.
Conclusion
In
short: it’s time some innovators in the AI space focused on its
security and privacy issues. With the world increasingly dependent on
these algorithms, there’s simply too much at stake — including a lot of
money for those who address these challenges.
Social
media and digital executives in newsrooms already have a tough job
connecting their content to consumers via social media, but Facebook’s proposed changes in the algorithms of its ‘newsfeed’
are going to make it a lot harder. Social networks offer immense
opportunities for reaching vast new audiences and increasing the
engagement of users with journalism. The most important platform in the
world is about to make that more difficult.
Clearly,
this is a blow for news publishers who have spent the last decade or so
fighting a battle for survival in a world where people’s attention and
advertising have shifted to other forms of content and away from news
media brand’s own sites. They are clearly very concerned. Yet, could this be a wake-up call that will mean the better, most adaptive news brands benefit?
I’m
not going to argue that this is good news for news publishers, but
blind panic or cynical abuse of Facebook is not a sufficient response.
The honest answer is that we don’t know exactly what the effect will be
because Facebook, as usual, have not given out the detail and different
newsrooms will be impacted differently.
It’s exactly the kind of issue we are looking at in our LSE Truth, Trust and Technology Commission.
Our first consultation workshop with journalists, and related
practitioners from sectors such as the platforms, is coming up in a few
weeks. This issue matters not just for the news business. It is also
central to the quality and accessibility of vital topical information
for the public.
Here’s my first attempt to unpack some of the issues.
Mark Zuckerberg: making time on Facebook ‘well spent’
Firstly,
this is not about us (journalists). Get real. Facebook is an
advertising revenue generation machine. It is a public company that has a
duty to maximise profits for its shareholders. It seeks people’s
attention so that it can sell it to advertisers. It has a sideline in
charging people to put their content on its platform, too. It is a
social network, not a news-stand. It was set up to connect ‘friends’ not
to inform people about current affairs. Journalism, even where shared
on Facebook, is a relatively small part of its traffic.
Clearly,
as Facebook has grown it has become a vital part of the global (and
local) information infrastructure. Other digital intermediaries such as
Google are vastly important, and other networks such as Twitter are
significant. And never forget that there are some big places such as
China where other similar networks dominate, not Facebook or other
western companies. But in many countries and for many demographics,
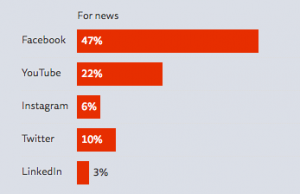
Facebook is the Internet, and the web is increasingly where people get their journalism. It’s a mixed and shifting picture but as the Reuters Digital News Report shows, Facebook is a critical source for news.
From Reuters Digital News Report 2017
If you read Zuckerberg’s statement he makes it clear that he is trying to make Facebook a more comfortable place to be:
“recently
we’ve gotten feedback from our community that public content — posts
from businesses, brands and media — is crowding out the personal moments
that lead us to connect more with each other.”
His users are ‘telling him’ (i.e. fewer of them are spending less time on FB) what a plethora of recent studies and books
have shown which is that using Facebook can make you miserable. News
content — which is usually ‘bad’ news — doesn’t cheer people up. The
angry, aggressive and divisive comment that often accompanies news
content doesn’t help with the good vibes. And while the viral spread of
so-called ‘fake news’ proves it is popular, it also contributes to the
sense that Facebook is a place where you can’t trust the news content.
Even when it is credible, it’s often designed to alarm and disturb. Not
nice. And Facebook wants nice.
“We
can’t make money unless you keep telling us things about yourself that
we can sell to advertisers. Please stop talking about news.”
Another
accusation is that Facebook is making these changes because of the
increasing costs it is expending at the behest of governments who are
now demanding it does more to fight misinformation and offensive
content. That might be a side-benefit for Facebook but I don’t think
it’s a key factor. It might even be a good thing for credible news if
the algorithmic changes include ways of promoting reliable content. But
overall the big picture is that journalism is being de-prioritised in
favour of fluffier stuff.
Even Jeff Jarvis, the US pioneer of digital journalism who has always sought to work with the grain of the platforms, admits that this is disturbing:
“I’m
worried that news and media companies — convinced by Facebook (and in
some cases by me) to put their content on Facebook or to pivot to
video — will now see their fears about having the rug pulled out from
under them realized and they will shrink back from taking journalism to
the people where they are having their conversations because there is no
money to be made there.”*
The
Facebook changes are going to be particularly tough on news
organisations that invested heavily in the ‘pivot to video’. These are
often the ‘digital native’ news brands who don’t have the spread of
outlets for their content that ‘legacy’ news organisations enjoy. The
BBC has broadcast. The Financial Times has a newspaper. These
organisations have gone ‘digital first’ but like the Economist they have
a range of social media strategies. And many of them, like the New York
Times, have built a subscription base. Email newsletters provide an
increasingly effective by-pass for journalism to avoid the social media
honey-trap. It all makes them less dependent on ‘organic’ reach through
Facebook.
But
Facebook will remain a major destination for news organisations to
reach people. News media still needs to be part of that. As the
ever-optimistic Jarvis also points out,
if these changes mean that Facebook becomes a more civil place where
people are more engaged, then journalism designed to fit in with that
culture might thrive more:
“journalism
and news clearly do have a place on Facebook. Many people learn what’s
going on in the world in their conversations there and on the other
social platforms. So we need to look how to create conversational news.
The platforms need to help us make money that way. It’s good for
everybody, especially for citizens.”
News
organisations need to do more — not just because of Facebook but also
on other platforms. People are increasingly turning to closed networks
or channels such as Whatsapp. Again, it’s tough, but journalism needs to
find new ways to be on those. I’ve written huge amounts
over the last ten years urging news organisations to be more networked
and to take advantage of the extraordinary connective, communicative
power of platforms such as Facebook. There has been brilliant
innovations by newsrooms over that period to go online, to be social and
to design content to be discovered and shared through the new networks.
But this latest change shows how the media environment continues to
change in radical ways and so the journalism must also be reinvented.
Social media journalist Esra Dogramaci has written an excellent article
on some of the detailed tactics that newsrooms can use to connect their
content to users in the face of technological developments like
Facebook’s algorithmic change:
“if
you focus on building a relationship with your audience and developing
loyalty, it doesn’t matter what the algorithm does. Your audience will
seek you out, and return to you over and over again. That’s how you
‘beat’ Facebook.”
Journalism Must Change
The
journalism must itself change. For example, it is clear that emotion is
going to be an even bigger driver of attention on Facebook after these
changes. The best journalism will continue to be factual and objective
at its core — even when it is campaigning or personal. But as I have written before,
a new kind of subjectivity can not only reach the hearts and minds of
people on places like Facebook, but it can also build trust and
understanding.
This
latest change by Facebook is dramatic, but it is a response to what
people ‘like’. There is a massive appetite for news — and not just
because of Trump or Brexit. Demand for debate and information has never
been greater or more important in people’s everyday lives. But we have
to change the nature of journalism not just the distribution and
discovery methods.
The media landscape is shifting to match people’s real media lives in our digital age. Another less noticed announcement from Facebook
last week suggested they want to create an ecosystem for local
personalised ‘news’. Facebook will use machine learning to surface news
publisher content at a local level. It’s not clear how they will vet
those publishers but clearly this is another opportunity for newsrooms
to engage. Again, dependency on Facebook is problematic, to put it
mildly, but ignoring this development is to ignore reality. The old
model of a local newspaper for a local area doesn’t effectively match
how citizens want their local news anymore.
What Facebook Must Do
Facebook
has to pay attention to the needs of journalism and as it changes its
algorithm to reduce the amount of ‘public content’ it has to work harder
at prioritising quality news content. As the Guardian’s outstanding
digital executive Chris Moran points out, there’s no indication from
Facebook that they have factored this into the latest change:
Fighting
‘fake news’ is not just about blocking the bad stuff, it is ultimately
best achieved by supporting the good content. How you do that is not a
judgement Facebook can be expected or relied upon to do by itself. It
needs to be much more transparent and collaborative with the news
industry as it rolls out these changes in its products.
When
something like Facebook gets this important to society, like any other
public utility, it becomes in the public interest to make policy to
maximise social benefits. This is why governments around the world are
considering and even enacting legislation or regulation regarding the
platforms, like Facebook. Much of this is focused on specific issues
such as the spread of extremist or false and disruptive information.
Rumu
is a very unique game, and of all the games on this list, I think it’s
the one that has the most unique UI. This is most likely due to the fact
that Rumu has pioneered the ‘Sentient Vaccuum Cleaner’ genre, and
there’s simply no game similar enough to pull inspiration from. Because
of this, I’ll briefly summarise the elements I liked the most, so you
have an idea of what I’m talking about.
It’s
fitting, then, that Rumu’s UI pulls from a number of different genres
and also remains quite unique. Rumu (The titular vacuum cleaner himself)
has a radial menu to manage it’s quest log and inventory. That’s about
where the traditional UI ends, and you start to see some bespoke
elements.
Tutorial
tips for controls appear outside the environments. This is a nice
detail, as it serves not only to communicate the key bind but also as a
hint of what you’re supposed to do in any given space.
A
similar method is used for doorways or vent spaces — each is earmarked
with text or iconography to indicate whether the player can pass
through. The difference is actually really important, because it serves
to split how the player treats information throughout the game — if the
information is inside the room, it’s something to be learned. If it
exists outside of the game space, it’s something that little Rumu
already knows.
There’s
a ‘Datavision’ function that allows Rumu to see how the various smart
devices and intractable objects connect. It’s a great way to declutter
the environments when the player is being task oriented, and it also
often hides hidden easter eggs or gadgets.
One
of the smartest UX features of Rumu is how it uses it’s palette and art
style to generate emotion. A clean, white kitchen feels calm and
simple, while crawling through vents on a sinister dark background gives
the game a sense of urgency and danger.
Rumu
is beautiful, functional, unique, and incredibly evocative. It’s UX
blends perfectly with the narrative of the game, and aids in the
storytelling.
Conclusion: Independent
developers are constantly coming up with new, interesting ways to
interact with their games. There’s even a few on this list: Hand of Fate
2 and Tooth of Tail both innovate in a well-trodden genre.
Rumu’s
a little different, because the robot vacuum cleaner genre isn’t quite
as mature as, say, first person shooters. Despite this, the interactions
in Rumu feel natural; the spacial and diagetic elements are what I’d
expect a robo-vacuum to see in the world, and the meta UI tips help move
the player along without breaking the (sometimes literal) fourth wall.
I look forward to seeing the robot vacuum cleaner genre evolve.
Worst: Stationeers
Picking
this game sparked an internal debate in my mind over having a ‘Worst’
section at all, but in the end I decided it’s always better to get your
feelings out than internalise them.
I
really enjoyed Stationeers; I played almost six hours straight in my
first run through. It’s an incredibly complex space space station
construction game. Most of it’s UI is inoffensive: a simple HUD with
your vitals and atmosphere stats, and a slot-based inventory system.
It
all falls apart for me in the item management. Rather than go into
specifics, I’ll give you an example: I need to take the empty battery
out of my welding torch, and replace it with a full one.
I
have to press 5 to open my tool belt, use the scroll wheel to highlight
the torch, press F to put it in my hand, press R to open the torch’s
inventory, press E to change hands, press F to move the batter into my
free hand.
Now
I press 2 to open my suit inventory, scroll wheel to an empty slot,
press F to place the flat batter in there. Scroll wheel to the full
battery, press F to place it in my off hand. Press E to change hands.
Press R to open the torch inventory. Press E to change hands. Press F to
place the battery in.
That’s…15 key presses. I can see what they were going for with this system, but there’s got to be a better way.
Virtual Reality
Best: Lone Echo
If
UX as a practice is still in it’s infancy, UX for VR is a single-celled
organism attempting mitosis for the first time. Nobody really has any
idea what’s going to work and what’s not going to work, and so many
games have great executions with a poor UX.
Lone
Echo feels like someone looking at what VR will be doing five years
from now, and dragged it screaming back into 2017. I don’t think it’s
hyperbole to say that Lone Echo’s UX will help define the future of
virtual and augmented reality interfaces.
There’s
no HUD in Lone Echo, instead opting to have your UI displayed from
various arm-mounted gadgetry. Jack, the player character, has a number
of controls and panels along his suit, each of which the player can
interact with to reveal various elements interfaces.
This
actually annoyed me at first — I wasn’t sure why a robot need any sort
of interface at all. However, the interactions available are just so
neat and genuinely enjoyable, it becomes a very small nitpick. You will
also witness other characters in the game use the same interface, which
gives some internal consistency to the game.
Talking
to someone, for example, is a matter of simply looking at them and
tapping a button the controller. This spawns a list of dialogue options
that you select with your finger. It’s a simple thing, but being able to
quickly interact with the object your looking at feels great.
Any
panels you summon are intractable with your hand. You can scroll and
tap like you would on an iPad. It feels completely natural to work with,
and there were very few times after the opening minutes where I had
trouble with this interaction style.
Similarly,
Jack’s wrist holds a number of functions and features that are
activated using your opposite hand. Slide across your forearm to open
your objectives. Tap the top of your wrist for your scanner, or the side
of your wrist for your welder. The interactions are so second-nature
after having used them a few times that I found myself not even looking
at my hands as I did these simple tasks.
Most
of what you see in Lone Echo comes from somewhere. The locomotion, the
dialogues, the tool interactions, are all borrowed from games that have
come before it. Lone Echo proves that these interactions are
unequivocally the right way to
do them, and if done right, can be so immersive and intuitive that the
player doesn’t have to remember them, they just become the way things are done.
Just like the brilliant writing and slick graphics, Lone Echo’s UX is the reason it’s
such a successful game. It keeps the player completely immersed in
everything they’re doing, no matter how complex the task. At it’s best,
the interactions in Lone Echo are actually fun to use. Menus that are fun! If that’s not a revolution, I don’t know what is.
Conclusion: The
most immersive experience I’ve ever had in a video game. Lone Echo
bends over backwards to put you in the moment with objects that behave
like the user expects they should, and an environment that is
consistently interactive.
Lone Echo isn’t held back by trying to
fit it’s UI into it’s narrative — it’s built it’s entire user
experience around the narrative, instead. Lone Echo sets the standard
for VR UX to come.
Worst: None
It’s
a cop out, I know. Truth be told, I haven’t played a VR game that
released in 2017 that had any truly awful UX. There’s plenty of games
that make some missteps, or the occasional obvious error, but this is
going to happen with a still-growing genre like virtual reality. For
now, VR gets a pass.
If
you got this far, thanks for reading! Hopefully you found something
interesting in my choices. Please feel free to comment with your
opinions, especially if there’s something great that I missed.
These
are my opinions on where deep neural network and machine learning is
headed in the larger field of artificial intelligence, and how we can
get more and more sophisticated machines that can help us in our daily
routines.
Please
note that these are not predictions of forecasts, but more a detailed
analysis of the trajectory of the fields, the trends and the technical
needs we have to achieve useful artificial intelligence.
Not
all machine learning is targeting artificial intelligences, and there
are low-hanging fruits, which we will examine here also.
Goals
The
goal of the field is to achieve human and super-human abilities in
machines that can help us in every-day lives. Autonomous vehicles, smart
homes, artificial assistants, security cameras are a first target. Home
cooking and cleaning robots are a second target, together with
surveillance drones and robots. Another one is assistants on mobile
devices or always-on assistants. Another is full-time companion
assistants that can hear and see what we experience in our life. One
ultimate goal is a fully autonomous synthetic entity that can behave at
or beyond human level performance in everyday tasks.
See more about these goals here, and here, and here.
Software
Software is defined here as neural networks architectures trained with an optimization algorithm to solve a specific task.
Today
neural networks are the de-facto tool for learning to solve tasks that
involve learning supervised to categorize from a large dataset.
But
this is not artificial intelligence, which requires acting in the real
world often learning without supervision and from experiences never seen
before, often combining previous knowledge in disparate circumstances
to solve the current challenge.
How do we get from the current neural networks to AI?
Neural network architectures
— when the field boomed, a few years back, we often said it had the
advantage to learn the parameters of an algorithms automatically from
data, and as such was superior to hand-crafted features. But we
conveniently forgot to mention one little detail… the neural network
architecture that is at the foundation of training to solve a specific
task is not learned from data! In fact it is still designed by hand.
Hand-crafted from experience, and it is currently one of the major
limitations of the field. There is research in this direction: here and here
(for example), but much more is needed. Neural network architectures
are the fundamental core of learning algorithms. Even if our learning
algorithms are capable of mastering a new task, if the neural network is
not correct, they will not be able to. The problem on learning neural
network architecture from data is that it currently takes too long to
experiment with multiple architectures on a large dataset. One has to
try training multiple architectures from scratch and see which one works
best. Well this is exactly the time-consuming trial-and-error procedure
we are using today! We ought to overcome this limitation and put more
brain-power on this very important issue.
Unsupervised learning
—we cannot always be there for our neural networks, guiding them at
every stop of their lives and every experience. We cannot afford to
correct them at every instance, and provide feedback on their
performance. We have our lives to live! But that is exactly what we do
today with supervised neural networks: we offer help at every instance
to make them perform correctly. Instead humans learn from just a handful
of examples, and can self-correct and learn more complex data in a
continuous fashion. We have talked about unsupervised learning
extensively here.
Predictive neural networks —
A major limitation of current neural networks is that they do not
possess one of the most important features of human brains: their
predictive power. One major theory about how the human brain work is by
constantly making predictions: predictive coding.
If you think about it, we experience it every day. As you lift an
object that you thought was light but turned out heavy. It surprises
you, because as you approached to pick it up, you have predicted how it
was going to affect you and your body, or your environment in overall.
Prediction
allows not only to understand the world, but also to know when we do
not, and when we should learn. In fact we save information about things
we do not know and surprise us, so next time they will not! And
cognitive abilities are clearly linked to our attention mechanism in the
brain: our innate ability to forego of 99.9% of our sensory inputs,
only to focus on the very important data for our survival — where is the
threat and where do we run to to avoid it. Or, in the modern world,
where is my cell-phone as we walk out the door in a rush.
Building
predictive neural networks is at the core of interacting with the real
world, and acting in a complex environment. As such this is the core
network for any work in reinforcement learning. See more below.
We
have talked extensively about the topic of predictive neural networks,
and were one of the pioneering groups to study them and create them. For
more details on predictive neural networks, see here, and here, and here.
Limitations of current neural networks
— We have talked about before on the limitation of neural networks as
they are today. Cannot predict, reason on content, and have temporal
instabilities — we need a new kind of neural networks that you can about read here.
Neural Network Capsules are one approach to solve the limitation of current neural networks. We reviewed them here. We argue here that Capsules have to be extended with a few additional features:
operation on video frames:
this is easy, as all we need to do is to make capsules routing look at
multiple data-points in the recent past. This is equivalent to an
associative memory on the most recent important data points. Notice
these are not the most recent representations of recent frames, but rather they are the top most recent different
representations. Different representations with different content can
be obtained for example by saving only representations that differ more
than a pre-defined value. This important detail allows to save relevant
information on the most recent history only, and not a useless series of
correlated data-points.
predictive neural network abilities:
this is already part of the dynamic routing, which forces layers to
predict the next layer representations. This is a very powerful
self-learning technique that in our opinion beats all other kinds of
unsupervised representation learning we have developed so far as a
community. Capsules need now to be able to predict long-term
spatiotemporal relationships, and this is not currently implemented.
Continuous learning
— this is important because neural networks need to continue to learn
new data-points continuously for their life. Current neural networks are
not able to learn new data without being re-trained from scratch at
every instance. Neural networks need to be able to self-assess the need
of new training and the fact that they do know something. This is also
needed to perform in real-life and for reinforcement learning tasks,
where we want to teach machines to do new tasks without forgetting older
ones.
Transfer learning
— or how do we have these algorithms learn on their own by watching
videos, just like we do when we want to learn how to cook something new?
That is an ability that requires all the components we listed above,
and also is important for reinforcement learning. Now you can really
train your machine to do what you want by just giving an example, the
same way we humans do every!
Reinforcement learning — this
is the holy grail of deep neural network research: teach machines how
to learn to act in an environment, the real world! This requires
self-learning, continuous learning, predictive power, and a lot more we
do not know. There is much work in the field of reinforcement learning,
but to the author it is really only scratching the surface of the
problem, still millions of miles away from it. We already talked about
this here.
Reinforcement
learning is often referred as the “cherry on the cake”, meaning that it
is just minor training on top of a plastic synthetic brain. But how can
we get a “generic” brain that then solve all problems easily? It is a
chicken-in-the-egg problem! Today to solve reinforcement learning
problems, one by one, we use standard neural networks:
a deep neural network that takes large data inputs, like video or audio and compress it into representations
a sequence-learning neural network, such as RNN, to learn tasks
Both
these components are obvious solutions to the problem, and currently
are clearly wrong, but that is what everyone uses because they are some
of the available building blocks.
As such results are unimpressive: yes we can learn to play video-games
from scratch, and master fully-observable games like chess and go, but I
do not need to tell you that is nothing compared to solving problems in
a complex world. Imagine an AI that can play Horizon Zero Dawn better than humans… I want to see that!
But this is what we want. Machine that can operate like us.
Our proposal for reinforcement learning work is detailed here. It uses a predictive neural network that can operate continuously and an associative memory to store recent experiences.
No more recurrent neural networks —
recurrent neural network (RNN) have their days counted. RNN are
particularly bad at parallelizing for training and also slow even on
special custom machines, due to their very high memory bandwidth
usage — as such they are memory-bandwidth-bound, rather than
computation-bound, see here for more details. Attention based neural network
are more efficient and faster to train and deploy, and they suffer much
less from scalability in training and deployment. Attention in neural
network has the potential to really revolutionize a lot of
architectures, yet it has not been as recognized as it should. The
combination of associative memories and attention is at the heart of the
next wave of neural network advancements.
Attention has already showed to be able to learn sequences as well as RNNs and at up to 100x less computation! Who can ignore that?
We
recognize that attention based neural network are going to slowly
supplant speech recognition based on RNN, and also find their ways in
reinforcement learning architecture and AI in general.
Localization of information in categorization neural networks — We have talked about how we can localize and detect key-points in images and video extensively here. This is practically a solved problem, that will be embedded in future neural network architectures.
Hardware
Hardware
for deep learning is at the core of progress. Let us now forget that
the rapid expansion of deep learning in 2008–2012 and in the recent
years is mainly due to hardware:
cheap image sensors in every phone allowed to collect huge datasets — yes helped by social media, but only to a second extent
GPUs allowed to accelerate the training of deep neural networks
And we have talked about hardware extensively before.
But we need to give you a recent update! Last 1–2 years saw a boom in
the are of machine learning hardware, and in particular on the one
targeting deep neural networks. We have significant experience here, and
we are FWDNXT, the makers of SnowFlake: deep neural network accelerator.
There
are several companies working in this space: NVIDIA (obviously), Intel,
Nervana, Movidius, Bitmain, Cambricon, Cerebras, DeePhi, Google,
Graphcore, Groq, Huawei, ARM, Wave Computing. All are developing custom
high-performance micro-chips that will be able to train and run deep
neural networks.
The
key is to provide the lowest power and the highest measured performance
while computing recent useful neural networks operations, not raw
theoretical operations per seconds — as many claim to do.
But
few people in the field understand how hardware can really change
machine learning, neural networks and AI in general. And few understand
what is important in micro-chips and how to develop them.
Here is our list:
training or inference? —
many companies are creating micro-chips that can provide training of
neural networks. This is to gain a portion of the market of NVIDIA,
which is the de-facto training hardware to date. But training is a small
part of the story and the applications of deep neural networks. For
every training step there are a million deployments in actual
applications. For example one of the object detection neural network you
can now use on the cloud today: it was trained once, and yes on a lot
of images, but once trained it can be use by millions of computers on
billions of data. What we are trying to say here: training hardware
matter as little as the number of times you trained compared to the
number of times you use. And making a chipset for training requires
extra hardware and extra tricks. This translates into higher power for
the same performance, and thus not the best possible for current
deployments. Training hardware is important, and a easy modification of
inference hardware, but it is not as important as many think.
Applications
— hardware that can provide training faster and at lower power is really
important in the field, because it will allow to create and test new
models and applications faster. But the real significant step forward
will be in hardware for applications, mostly in inference. There are
many applications today that are not possible or practical because
hardware, and not software, is missing or inefficient. For example our
phones can be speech-based assistants, and are currently sub-optimal
because they cannot operate always-on. Even our home assistants are tied
to the power supplies, and cannot follow us around the house unless we
sprinkle multiple microphones or devices around. But maybe the largest
application of all is removing the phone screen from our lives, and
embedding it into our visual system. Without super-efficient hardware
all this and many more applications (small robots) will not be possible.
winners and losers
— in hardware, the winner will be the ones that can operate at the
lowest possible power per unit performance, and move into the market
quickly. Imagine replacing SoC in cell-phones. Happens every year. Now
imagine embedding neural network accelerators into memories. This may
conquer much of the market faster and with significant penetration. That
is what we call a winner.
About neuromorphic neural networks hardware, please see here.
Applications
We
talked briefly about applications in the Goals section above, but we
really need to go into details here. How is AI and neural network going
to get into our daily life?
Here is our list:
categorizing images and videos
— already here in many cloud services. The next steps are doing the same
in smart camera feeds — also here today from many providers. Neural
nets hardware will allow to remove the cloud and process more and more
data locally: a winner for privacy and saving Internet bandwidth.
speech-based assistants
— they are becoming a part of our lives, as they play music and control
basic devices in our “smart” homes. But dialogue is such a basic human
activity, we often give it for granted. Small devices you can talk to
are a revolution that is
happening right now. Speech-based assistants are getting better and
better at serving us. But they are still tied to the power grid. The
real assistant we want is moving with us. How about our cell-phone? Well
again hardware wins here, because it will make that possible. Alexa and
Cortana and Siri will be always on and always with you. Your phone will
be your smart home — very soon. That is again another victory of the
smart phone. But we also want it in our car and as we move around town.
We need local processing of voice, and less and less cloud. More privacy
and less bandwidth costs. Again hardware will give us all that in 1–2
years.
the real artificial assistants
— voice is great, but what we really want is something that can also see
what we see. Analyze our environment as we move around. See an example here and ultimately here.
This is the real AI assistant we can fall in love with. And neural
network hardware will again grant your wish, as analyzing video feed is
very computationally expensive, and currently at the theoretical limits
on current silicon hardware. In other words a lot harder to do than
speech-based assistants. But it is not impossible, and many smart
startups like AiPoly
already have all the software for it, but lack powerful hardware for
running it on phones. Notice also that replacing the phone screen with a
wearable glasses-like device will really make our assistant part of us!
the cooking robot — the next biggest appliances will be a cooking and cleaning robot.
Here we may soon have the hardware, but we are clearly lacking the
software. We need transfer learning, continuous learning and
reinforcement learning. All working like a charm. Because you see: every
recipe is different, every cooking ingredient looks different. We
cannot hard-code all these options. We really need a synthetic entity
that can learn and generalize well to do this. We are far from it, but
not as far. Just a handful of years away at the current pace of
progress. I sure will work on this, as I have done in the last few
years~
My colleagues and I wanted to create something that would make people go “wow” at our latest hackathon.
Because
imitation is the sincerest form of flattery and IoT is incredibly fun
to work with, we decided to create our own version of Amazon Go.
Before I explain what it took to make this, here’s the 3 minute demo of what we built!
There were four of us. Ruslan,
a great full-stack developer who had experience working with Python.
John, an amazing iOS developer. Soheil, another great full-stack
developer who had experience with Raspberry Pi. And finally, there was
me, on the tail end of an Android developer internship.
I
quickly realized that there were a lot of moving parts to this project.
Amazon Go works on the basis of real-time proximity sensors in
conjunction with a real-time database of customers and their carts.
We
also wanted to take things a step further and make the entry/exit
experience seamless. We wanted to let people enter and exit the store
without needing to tap their phones.
In
order to engage users as a consumer-facing product, our app would need a
well-crafted user interface, like the real Amazon Go.
On
the day before the hackathon, I put together a pseudo-design doc
outlining what we needed to do within the 36 hour deadline. I
incorporated the strengths of our team and the equipment at hand. The
full hastily assembled design doc can be seen below.
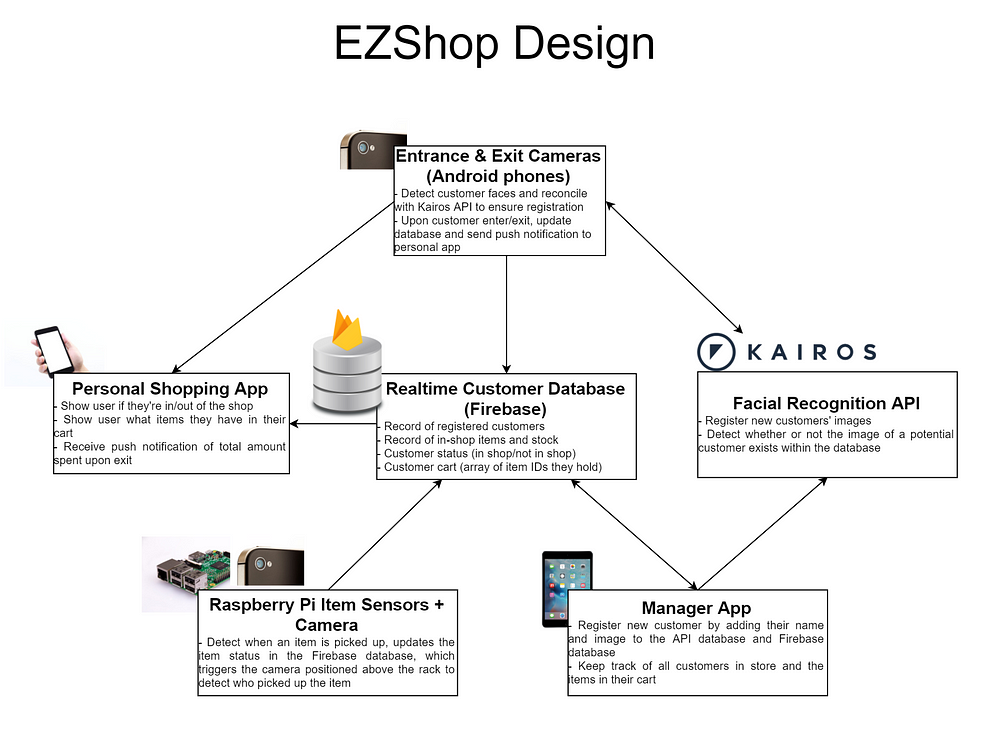
There were six main components to EZShop, our version of Amazon Go.
A quick diagram I whipped up visualizing the components of this project
The Kairos Facial Recognition API
The Kairos facial recognition API
was a fundamental component for us. It abstracted the ability to
identify and store unique faces. It had two APIs that we used: /enroll and /verify.
/enroll is described as:
Takes a photo, finds the faces within it, and stores the faces into a gallery you create.
We enrolled all new customers into a single “EZShop” gallery. A unique face_id attribute would be returned and stored with the customer’s registered name in our real-time database.
When we wanted to verify a potential customer’s image, we would POST it to the /verify endpoint. This would return the face_id with the highest probability of a match.
In
a real-world implementation, it probably would have been a better idea
to use a natively implemented facial recognition pipeline with
TensorFlow instead of a network API. But given our time constraints, the
API served us very well.
The Realtime Firebase Database
The
Firebase database was another fundamental piece to our puzzle. Every
other component interacted with it in real time. Firebase allows
customized change listeners to be created upon any data within the
database. That feature, coupled with the easy set-up process, made it a
no brainer to use.
The
schema was incredibly simple. The database stored an array of items and
an array of users. The following is an example JSON skeleton of our
database:
New users would be added to the array of users in our database after registering with the Kairos API. Upon entry or exit, the customer’s boolean in_store attribute would be updated, which would be reflected in the manager and personal app UIs.
Customers picking up an item would result in an updated item stock. Upon recognizing which customer picked up what item, the item’s ID would be added to the customer’s items_picked_up array.
I had planned for a cloud-hosted Node/Flask server that would route all activity from one device to another, but the team decided that it was much more efficient (although more hacky) for everybody to work directly upon the Firebase database.
The Manager and Personal Customer Apps
John, being the iOS wizard that he is, finished these applications in the first 12 hours of the hackathon! He really excelled at designing user-friendly and accessible apps.
The Manager App
This iPad application registered new customers into our Kairos API and Firebase database. It also displayed all customers in the store and the inventory of store items. The ability to interact directly with the Firebase database and observe changes made to it (e.g. when a customer’s in_store attribute changes from true to false) made this a relatively painless process. The app was a great customer-facing addition to our demo.
The Personal Shopping App
Once the customer was registered, we would hand a phone with this app installed to the customer. They would log in with their face (Kairos would recognize and authenticate). Any updates to their cart would be shown on the phone instantly. Upon exiting the store, the customer would also receive a push notification on this phone stating the total amount they spent.
The Item Rack, Sensors, and Camera
Soheil and Ruslan worked tirelessly for hours to perfect the design of the item shelf apparatus and the underlying Pi Python scripts.
The item rack apparatus. Three items positioned in rows, a tower for the security camera, and ultrasonic sensors positioned at the rear
There were three items positioned in rows. At the end of two rows, an ultrasonic proximity sensor was attached. We only had two ultrasonic sensors, so the third row had a light sensor under the items, which did not work as seamlessly. The ultrasonic sensors were connected to the Raspberry Pi that processed the readings of the distance from the next closest object via simple Python scripts (either the closest item or the end of the rack). The light sensor detected a “dark” or “light” state (dark if the item was on top of it, light otherwise).
When an item was lifted, the sensor’s reading would change and trigger an update to the item’s stock in the database. The camera (Android phone) positioned at the top of the tower would detect this change and attempt to recognize the customer picking up the item. The item would then instantly be added to that customer’s cart.
Entrance and Exit Cameras
I opted to use Android phones as our facial recognition cameras, due to my relative expertise with Android and the easy coupling phones provide when taking images and processing them.
The phones were rigged on both sides of a camera tripod, one side at the store’s entrance, and the other at the store exit.
A camera tripod, two phones, and lots of tape
Google has an incredibly useful Face API that implements a native pipeline for detecting human faces and other related useful attributes. I used this API to handle the heavy lifting for facial recognition.
In particular, the API provided an approximate distance of a detected face from the camera. Once a customer’s face was within a close distance, I would take a snapshot of the customer, verify it against the Kairos API to ensure the customer existed in our database, and then update the Firebase database with the customer’s in-store status.
I also added a personalized text-to-speech greeting upon recognizing the customer. That really ended up wowing everybody who used it.
The result of this implementation can be seen here:
Once the customer left the store, the exit-detection state of the Android application was responsible for retrieving the items the customer picked up from the database, calculating the total amount the customer spent, and then sending a push notification to the customer’s personal app via Firebase Cloud Messaging.
Of the 36 hours, we slept for about 6. We spent our entire time confined to a classroom in the middle of downtown Toronto. There were countless frustrating bugs and implementation roadblocks we had to overcome. There were some bugs in our demo that you probably noticed, such as the cameras failing to recognize several people in the same shot.
We would have also liked to implement additional features, such as detecting customers putting items back on the rack and adding a wider variety of items.
Our project ended up winning first place at the hackathon. We set up an interactive booth for an hour (the Chipotle box castle that can be seen in the title picture) and had over a hundred people walk through our shop. People would sign up with a picture, log into the shopping app, walk into the store, pick up an item, walk out, and get notified of their bill instantly. No cashiers, no lines, no receipts, and a very enjoyable user experience.
Walking a customer through our shop
I was proud of the way our team played to each individual’s strengths and created a well put-together full-stack IoT project in the span of a few hours. It was an incredibly rewarding feeling for everybody, and it’s something I hope to replicate in my career in the future.
I hope this gave you some insight into what goes on behind the scenes of a large, rapidly prototyped, and hacky hackathon project such as EZShop.
Hardik Gandhi is Master of Computer science,blogger,developer,SEO provider,Motivator and writes a Gujarati and Programming books and Advicer of career and all type of guidance.