The 8 Neural Network Architectures Machine
Learning Researchers Need to Learn
The Historical Development of Machine Learning’s Core Structure
Why do we need Machine Learning?
Machine
learning is needed for tasks that are too complex for humans to code
directly. Some tasks are so complex that it is impractical, if not
impossible, for humans to work out all of the nuances and code for them
explicitly. So instead, we provide a large amount of data to a machine
learning algorithm and let the algorithm work it out by exploring that
data and searching for a model that will achieve what the programmers
have set it out to achieve.
Let’s look at these 2 examples:
- It is very hard to write programs that solve problems like recognizing a 3-dimensional object from a novel viewpoint in new lighting conditions in a cluttered scene. We don’t know what program to write because we don’t know how it’s done in our brain. Even if we had a good idea about how to do it, the program might be horrendously complicated.
- It is hard to write a program to compute the probability that a credit card transaction is fraudulent. There may not be any rules that are both simple and reliable. We need to combine a very large number of weak rules. Fraud is a moving target but the program needs to keep changing.
Then comes the Machine Learning Approach:
Instead of writing a program by hand for each specific task, we collect
lots of examples that specify the correct output for a given input. A
machine learning algorithm then takes these examples and produces a
program that does the job. The program produced by the learning
algorithm may look very different from a typical hand-written program.
It may contain millions of numbers. If we do it right, the program works
for new cases as well as the ones we trained it on. If the data changes
the program can change too by training on the new data. You should note
that massive amounts of computation are now cheaper than paying someone
to write a task-specific program.
Given that, some examples of tasks best solved by machine learning include:
- Recognizing patterns: Objects in real scenes, Facial identities or facial expressions, Spoken words
- Recognizing anomalies: Unusual sequences of credit card transactions, Unusual patterns of sensor readings in a nuclear power plant
- Prediction: Future stock prices or currency exchange rates, Which movies will a person like
What are Neural Networks?
Neural
networks are a class of models within the general machine learning
literature. So for example, if you took a Coursera course on machine
learning, neural networks will likely be covered. Neural networks are a
specific set of algorithms that has revolutionized the field of machine
learning. They are inspired by biological neural networks and the
current so called deep neural networks have proven to work quite very
well. Neural Networks are themselves general function approximations,
that is why they can be applied to literally almost any machine learning
problem where the problem is about learning a complex mapping from the
input to the output space.
Here are the 3 reasons to convince you to study neural computation:
- To understand how the brain actually works: It’s very big and very complicated and made of stuff that dies when you poke it around. So we need to use computer simulations.
- To understand a style of parallel computation inspired by neurons and their adaptive connections: It’s a very different style from a sequential computation.
- To solve practical problems by using novel learning algorithms inspired by the brain: Learning algorithms can be very useful even if they are not how the brain actually works.
After finishing the famous Andrew Ng’s Machine Learning Coursera course,
I started developing interest towards neural networks and deep
learning. Thus, I started looking at the best online resources to learn
about the topics and found Geoffrey Hinton’s Neural Networks for Machine Learning course.
If you are a deep learning practitioner or someone who want to get into
the deep learning/machine learning world, you should really take this
course. Geoffrey Hinton is without a doubt a godfather of the deep
learning world. And he actually provided something extraordinary in this
course. In this blog post, I want to share the 8 neural network architectures from the course that I believe any machine learning researchers should be familiar with to advance their work.

Generally, these architectures can be put into 3 specific categories:
1 — Feed-Forward Neural Networks
These
are the commonest type of neural network in practical applications. The
first layer is the input and the last layer is the output. If there is
more than one hidden layer, we call them “deep” neural networks. They
compute a series of transformations that change the similarities between
cases. The activities of the neurons in each layer are a non-linear
function of the activities in the layer below.
2 — Recurrent Networks
These
have directed cycles in their connection graph. That means you can
sometimes get back to where you started by following the arrows. They
can have complicated dynamics and this can make them very difficult to
train. They are more biologically realistic.
There
is a lot of interest at present in finding efficient ways of training
recurrent nets. Recurrent neural networks are a very natural way to
model sequential data. They are equivalent to very deep nets with one
hidden layer per time slice; except that they use the same weights at
every time slice and they get input at every time slice. They have the
ability to remember information in their hidden state for a long time
but is very hard to train them to use this potential.
3 — Symmetrically Connected Networks
These
are like recurrent networks, but the connections between units are
symmetrical (they have the same weight in both directions). Symmetric
networks are much easier to analyze than recurrent networks. They are
also more restricted in what they can do because they obey an energy
function. Symmetrically connected nets without hidden units are called
“Hopfield Nets.” Symmetrically connected network with hidden units are
called “Boltzmann machines.”
1 — Perceptrons
Considered the first generation of neural networks, perceptrons are simply computational models of a single neuron. They were popularized by Frank Rosenblatt
in the early 1960s. They appeared to have a very powerful learning
algorithm and lots of grand claims were made for what they could learn
to do. In 1969, Minsky and Papers published a book called “Perceptrons”
that analyzed what they could do and showed their limitations. Many
people thought these limitations applied to all neural network models.
However, the perceptron learning procedure is still widely used today
for tasks with enormous feature vectors that contain many millions of
features.
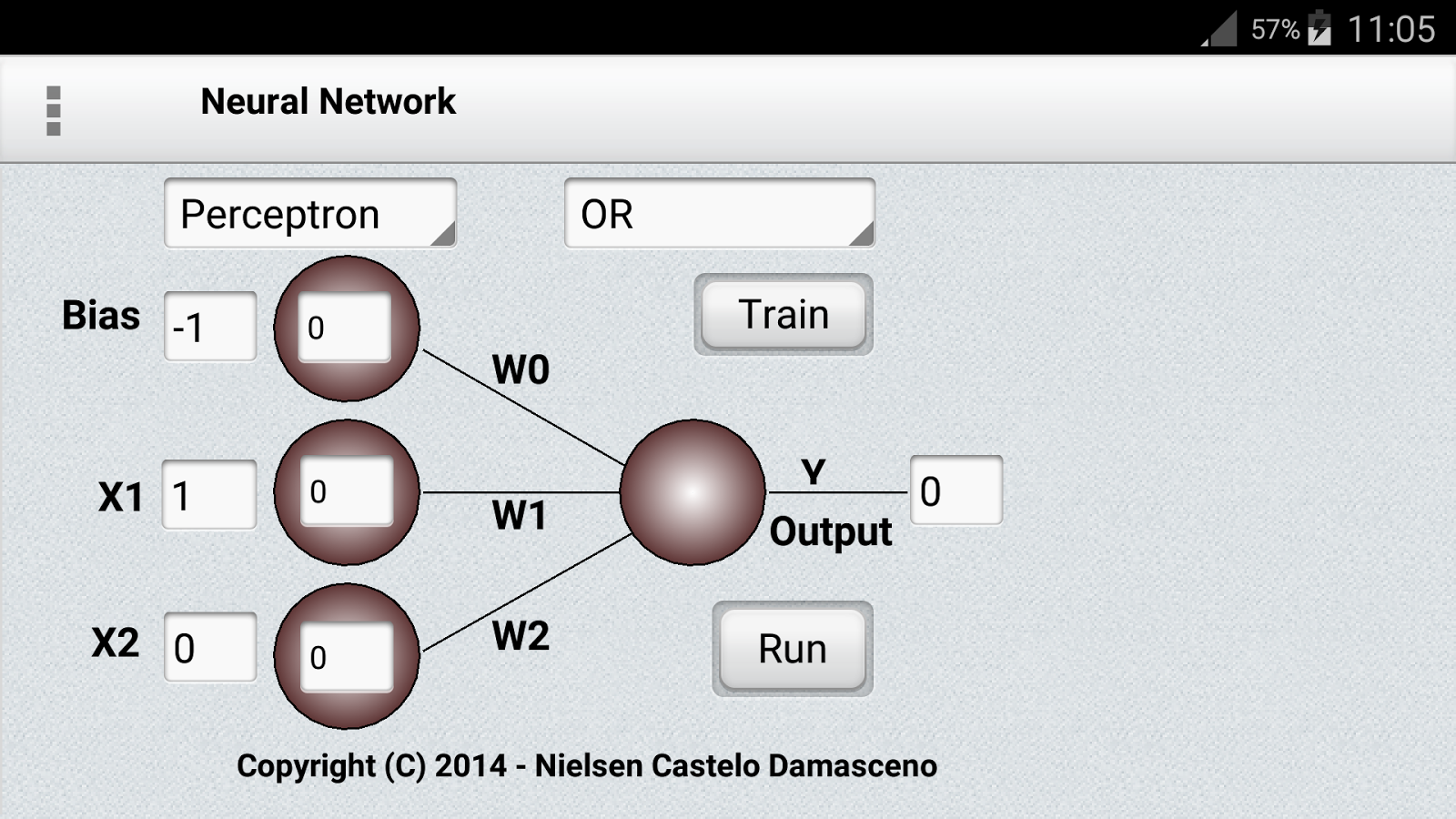
In
the standard paradigm for statistical pattern recognition, we first
convert the raw input vector into a vector of feature activations. We
then use hand-written programs based on common-sense to define the
features. Next, we learn how to weight each of the feature activations
to get a single scalar quantity. If this quantity is above some
threshold, we decide that the input vector is a positive example of the
target class.
The
standard Perceptron architecture follows the feed-forward model,
meaning inputs are sent into the neuron, are processed, and result in an
output. In the diagram below, this means the network reads bottom-up:
input comes in from the bottom and output goes out from the top.
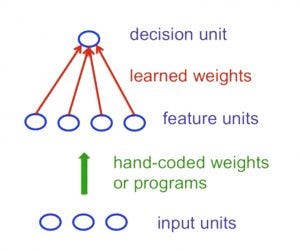
However,
Perceptrons do have limitations: If you are followed to choose the
features by hand and if you use enough features, you can do almost
anything. For binary input vectors, we can have a separate feature unit
for each of the exponentially many binary vectors and so we can make any
possible discrimination on binary input vectors. But once the
hand-coded features have been determined, there are very strong
limitations on what a perceptron can learn.
This
result is devastating for Perceptrons because the whole point of
pattern recognition is to recognize patterns despite transformations
like translation. Minsky and Papert’s “Group Invariance Theorem” says
that the part of a Perceptron that learns cannot learn to do this if the
transformations form a group. To deal with such transformations, a
Perceptron needs to use multiple feature units to recognize
transformations of informative sub-patterns. So the tricky part of
pattern recognition must be solved by the hand-coded feature detectors,
not the learning procedure.
Networks
without hidden units are very limited in the input-output mappings they
can learn to model. More layers of linear units do not help. It’s still
linear. Fixed output non-linearities are not enough. Thus, we need
multiple layers of adaptive, non-linear hidden units. But how we train
such nets? We need an efficient way of adapting all the weights, not
just the last layer. This is hard. Learning the weights going into
hidden units is equivalent to learning features. This is difficult
because nobody is telling us directly what the hidden units should do.
2 — Convolutional Neural Networks
Machine
Learning research has focused extensively on object detection problems
over the time. There are various things that make it hard to recognize
objects:
- Segmentation: Real scenes are cluttered with other objects. It’s hard to tell which pieces go together as parts of the same object. Parts of an object can be hidden behind other objects.
- Lighting: The intensities of the pixels are determined as much by the lighting as by the objects.
- Deformation: Objects can deform in a variety of non-affine ways. E.g., a handwritten too can have a large loop or just a cusp.
- Affordances: Object classes are often defined by how they are used. E.g., chairs are things designed for sitting on so they have a wide variety of physical shapes.
- Viewpoint: Changes in viewpoint cause changes in images that standard learning methods cannot cope with. Information hops between input dimensions (i.e. pixels)
- Imagine a medical database in which the age of a patient sometimes hopes to the input dimension that normally codes for weight! To apply machine learning we would first want to eliminate this dimension-hopping.
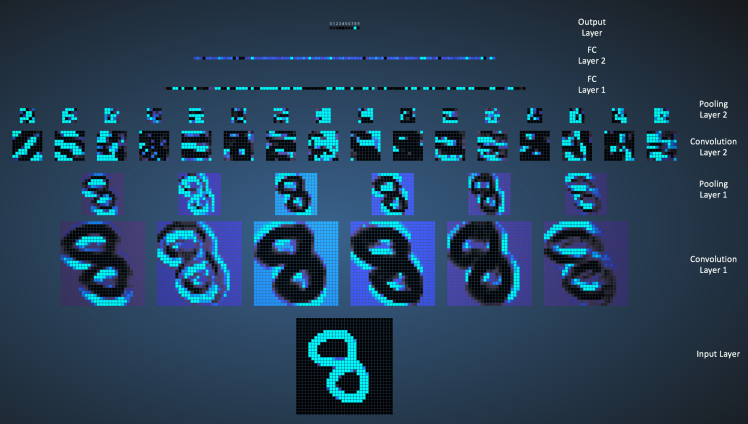
The
replicated feature approach is currently the dominant approach for
neural networks to solve object detection problem. It uses many
different copies of the same feature detector with different positions.
It could also replicate across scale and orientation, which is tricky
and expensive. Replication greatly reduces the number of free parameters
to be learned. It uses several different feature types, each with its
own map of replicated detectors. It also allows each patch of image to
be represented in several ways.
So what does replicating the feature detectors achieve?
- Equivalent activities: Replicated features do not make the neural activities invariant to translation. The activities of are equivariant.
- Invariant knowledge: If a feature is useful in some locations during training, detectors for that feature will be available in all locations during testing.
In 1998, Yann LeCun and his collaborators developed a really good recognizer for handwritten digits called LeNet.
It used back propagation in a feedforward net with many hidden layers,
many maps of replicated units in each layer, pooling of the outputs of
nearby replicated units, a wide net that can cope with several
characters at once even if they overlap, and a clever way of training a
complete system, not just a recognizer. Later it is formalized under the
name convolutional neural networks. Fun fact: This net was used for reading ~10% of the checks in North America.
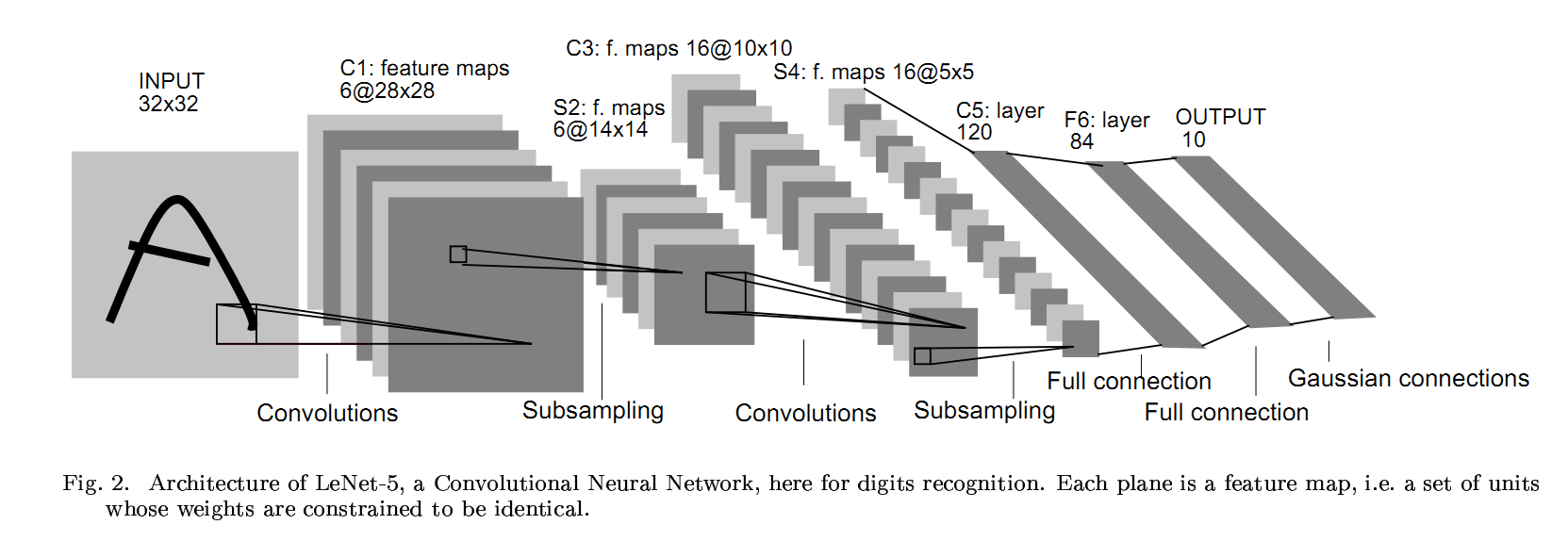
Convolutional
Neural Networks can be used for all work related to object recognition
from hand-written digits to 3D objects. However, recognizing real
objects in color photographs downloaded from the web is much more
complicated than recognizing hand-written digits. There are hundred
times as many classes (1000 vs 10), hundred times as many pixels (256 x
256 color vs 28 x 28 gray), two-dimensional images of three-dimensional
scenes, cluttered scenes requiring segmentation, and multiple objects in
each image. Will the same type of convolutional neural network work?
Then came the ILSVRC-2012 competition on ImageNet,
a dataset with approximately 1.2 million high-resolution training
images. Test images will be presented with no initial annotation (no
segmentation or labels) and algorithms will have to produce labelings
specifying what objects are present in the images. Some of the best
existing computer vision methods were tried on this dataset by leading
computer vision groups from Oxford, INRIA, XRCE… Typically, computer
vision systems use complicated multi-stage systems and the early stages
are typically hand-tuned by optimizing a few parameters.

The winner of the competition, Alex Krizhevsky (NIPS 2012),
developed a very deep convolutional neural net of the type pioneered by
Yann LeCun. Its architecture includes 7 hidden layers not counting some
max-pooling layers. The early layers were convolutional, while the last
2 layers were globally connected. The activation functions were
rectified linear units in every hidden layer. These train much faster
and are more expressive than logistic units. In addition to that, it
also uses competitive normalization to suppress hidden activities when
nearby units have stronger activities. This helps with variations in
intensity.
There are a couple of technical tricks that significantly improve generalization for the neural net:
- Training on random 224 x 224 patches from the 256 x 256 images to get more data and using left-right reflections of the images. At test time, combining the opinions from 10 different patches: The four 224 x 224 corner patches plus the central 224 x 224 patch plus the reflections of those 5 patches.
- Using “dropout” to regularize the weights in the globally connected layers (which contain most of the parameters). Dropout means that half of the hidden units in a layer are randomly removed for each training example. This stops hidden units from relying too much on other hidden units.
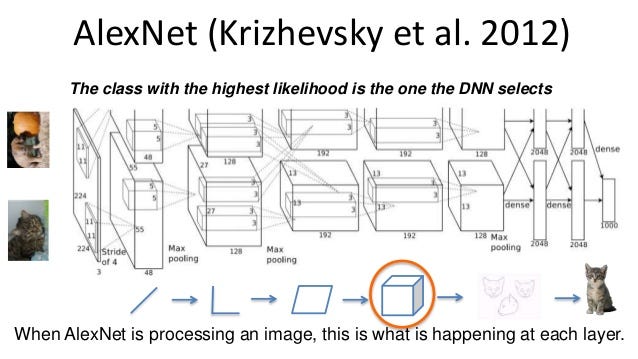
In
terms of hardware requirement, Alex uses a very efficient
implementation of convolutional nets on 2 Nvidia GTX 580 GPUs (over 1000
fast little cores). The GPUs are very good for matrix-matrix multiplies
and also have very high bandwidth to memory. This allows him to train
the network in a week and makes it quick to combine results from 10
patches at test time. We can spread a network over many cores if we can
communicate the states fast enough. As cores get cheaper and datasets
get bigger, big neural nets will improve faster than old-fashioned
computer vision systems.
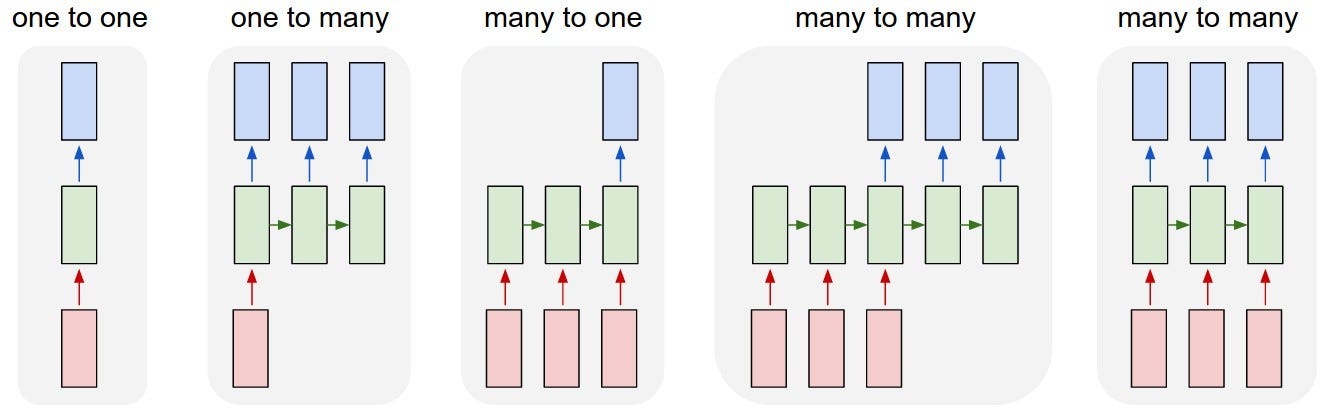
3 — Recurrent Neural Network
To
understand RNNs, we need to have a brief overview of sequence modeling.
When applying machine learning to sequences, we often want to turn an
input sequence into an output sequence that lives in a different domain;
for example, turn a sequence of sound pressures into a sequence of word
identities. When there is no separate target sequence, we can get a
teaching signal by trying to predict the next term in the input
sequence. The target output sequence is the input sequence with an
advance of 1 step. This seems much more natural than trying to predict
one pixel in an image from the other pixels, or one patch of an image
from the rest of the image. Predicting the next term in a sequence blurs
the distinction between supervised and unsupervised learning. It uses
methods designed for supervised learning, but it doesn’t require a
separate teaching signal.
Memoryless models
are the standard approach to this task. In particular, autoregressive
models can predict the next term in a sequence from a fixed number of
previous terms using “delay taps; and feed-forward neural nets are
generalized autoregressive models that use one or more layers of
non-linear hidden units. However, if we give our generative model some
hidden state, and if we give this hidden state its own internal
dynamics, we get a much more interesting kind of model: It can store
information in its hidden state for a long time. If the dynamics are
noisy and the way they generate outputs from their hidden state is
noisy, we can never know its exact hidden state. The best we can do is
to infer a probability distribution over the space of hidden state
vectors. This inference is only tractable for 2 types of hidden state
model.
Recurrent Neural Networks are
very powerful, because they combine 2 properties: 1) distributed hidden
state that allows them to store a lot of information about the past
efficiently, and 2) non-linear dynamics that allow them to update their
hidden state in complicated ways. With enough neurons and time, RNNs can
compute anything that can be computed by your computer. So what kinds
of behavior can RNNs exhibit? They can oscillate, they can settle to
point attractors, they can behave chaotically. And they could
potentially learn to implement lots of small programs that each capture a
nugget of knowledge and run in parallel, interacting to produce very
complicated effects.
However,
the computational power of RNNs makes them very hard to train. It is
quite difficult to train a RNN because of the exploding or vanishing
gradients problem. As we backpropagate through many layers, what happens
to the magnitude of the gradients? If the weights are small, the
gradients shrink exponentially. If the weights are big, the gradients
grow exponentially. Typical feed-forward neural nets can cope with these
exponential effects because they only have a few hidden layers. On the
other hand, in a RNN trained on long sequences, the gradients can easily
explode or vanish. Even with good initial weights, it’s very hard to
detect that the current target output depends on an input from many
time-steps ago, so RNNs have difficulty dealing with long-range
dependencies.
There are essentially 4 effective ways to learn a RNN:
- Long Short Term Memory: Make the RNN out of little modules that are designed to remember values for a long time.
- Hessian Free Optimization: Deal with the vanishing gradients problem by using a fancy optimizer that can detect directions with a tiny gradient but even smaller curvature.
- Echo State Networks: Initialize the input -> hidden and hidden -> hidden and output -> hidden connections very carefully so that the hidden state has a huge reservoir of weakly coupled oscillators which can be selectively driven by the input.
- Good initialization with momentum: Initialize like in Echo State Networks, but then learn all of the connections using momentum.
4 — Long/Short Term Memory Network
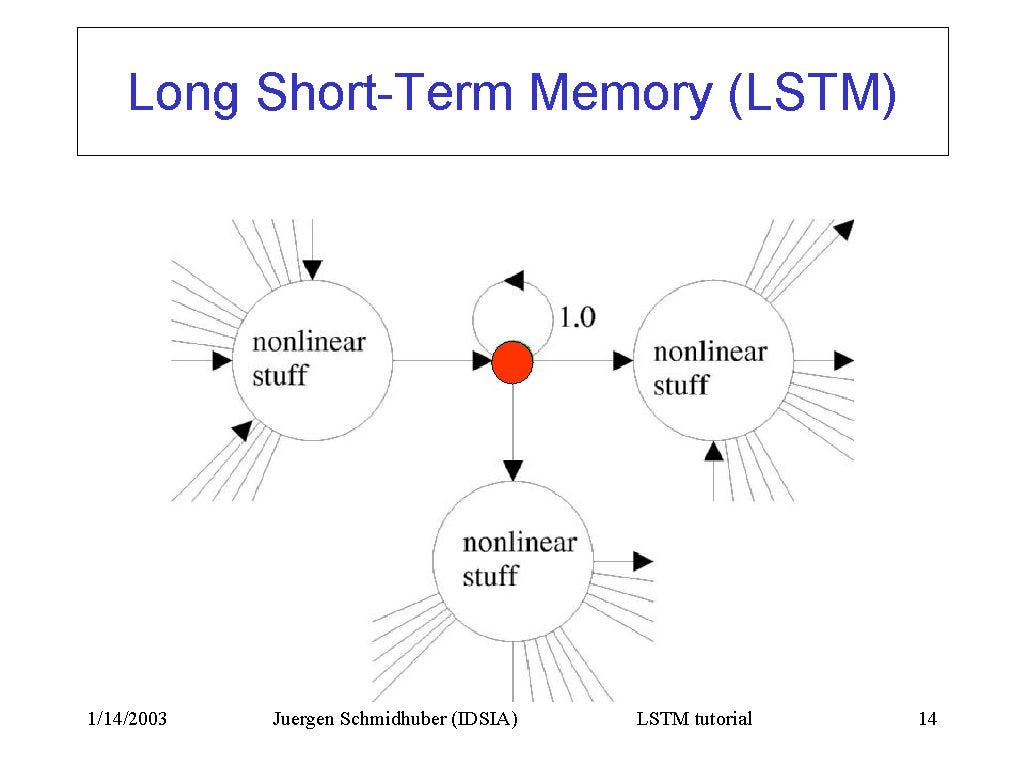
Hochreiter & Schmidhuber (1997) solved the problem of getting a RNN to remember things for a long time (like hundreds of time steps) by building what known as long-short term memory network. They
designed a memory cell using logistic and linear units with
multiplicative interactions. Information gets into the cell whenever its
“write” gate is on. The information stays in the cell so long as its
“keep” gate is on. Information can be read from the cell by turning on
its “read” gate.
Reading
cursive handwriting is a natural task for an RNN. The input is a
sequence of (x, y, p) coordinates of the tip of the pen, where p
indicates whether the pen is up or down. The output is a sequence of
characters. Graves & Schmidhuber (2009)
showed that RNNs with LSTM are currently the best systems for reading
cursive writing. In brief, they used a sequence of small images as input
rather than pen coordinates.
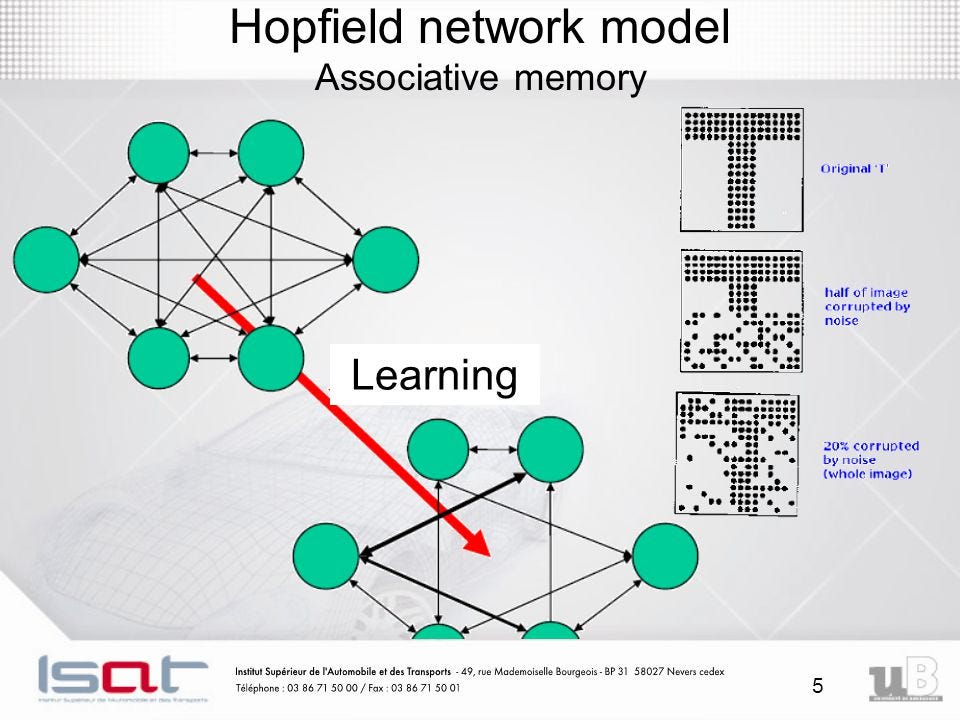
5 — Hopfield Networks
Recurrent
networks of non-linear units are generally very hard to analyze. They
can behave in many different ways: settle to a stable state, oscillate,
or follow chaotic trajectories that cannot be predicted far into the
future. A Hopfield net is composed of binary threshold units with recurrent connections between them. In 1982, John Hopfield
realized that if the connections are symmetric, there is a global
energy function. Each binary “configuration” of the whole network has an
energy; while the binary threshold decision rule causes the network to
settle for a minimum of this energy function. A neat way to make use of
this type of computation is to use memories as energy minima for the
neural net. Using energy minima to represent memories gives a
content-addressable memory. An item can be accessed by just knowing part
of its content. It is robust against hardware damage.
Each
time we memorize a configuration, we hope to create a new energy
minimum. But what if two nearby minima at an intermediate location? This
limits the capacity of a Hopfield net. So how do we increase the
capacity of a Hopfield net? Physicists love the idea that the math they
already know might explain how the brain works. Many papers were
published in physics journals about Hopfield nets and their storage
capacity. Eventually, Elizabeth Gardnerfigured
out that there was a much better storage rule that uses the full
capacity of the weights. Instead of trying to store vectors in one shot,
she cycled through the training set many times and used the perceptron
convergence procedure to train each unit to have the correct state given
the states of all the other units in that vector. Statisticians call
this technique “pseudo-likelihood.”
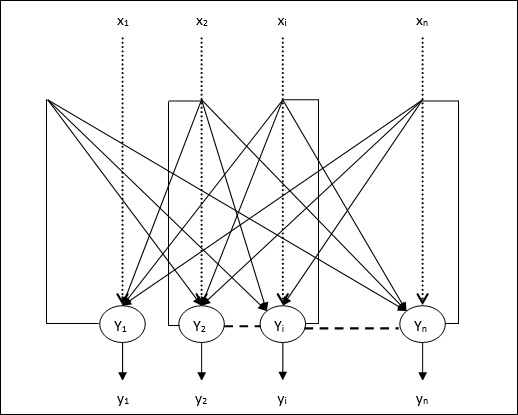
There
is another computational role for Hopfield nets. Instead of using the
net to store memories, we use it to construct interpretations of sensory
input. The input is represented by the visible units, the
interpretation is represented by the states of the hidden units, and the
badness of the interpretation is represented by the energy.
6 — Boltzmann Machine Network
A Boltzmann machine
is a type of stochastic recurrent neural network. It can be seen as the
stochastic, generative counterpart of Hopfield nets. It was one of the
first neural networks capable of learning internal representations and
is able to represent and solve difficult combinatoric problems.
The
goal of learning for Boltzmann machine learning algorithm is to
maximize the product of the probabilities that the Boltzmann machine
assigns to the binary vectors in the training set. This is equivalent to
maximizing the sum of the log probabilities that the Boltzmann machine
assigns to the training vectors. It is also equivalent to maximizing the
probability that we would obtain exactly the N training cases if we did
the following: 1) Let the network settle to its stationary distribution
N different time with no external input; and 2) Sample the visible
vector once each time.
An efficient mini-batch learning procedure was proposed for Boltzmann Machines by Salakhutdinov and Hinton in 2012.
- For the positive phase, first initialize the hidden probabilities at 0.5, then clamp a data vector on the visible units, then update all the hidden units in parallel until convergence using mean field updates. After the net has converged, record PiPj for every connected pair of units and average this over all data in the mini-batch.
- For the negative phase: first keep a set of “fantasy particles.” Each particle has a value that is a global configuration. Then sequentially update all the units in each fantasy particle a few times. For every connected pair of units, average SiSj over all the fantasy particles.
In
a general Boltzmann machine, the stochastic updates of units need to be
sequential. There is a special architecture that allows alternating
parallel updates which are much more efficient (no connections within a
layer, no skip-layer connections). This mini-batch procedure makes the
updates of the Boltzmann machine more parallel. This is called a Deep
Boltzmann Machine (DBM), a general Boltzmann machine with a lot of
missing connections.
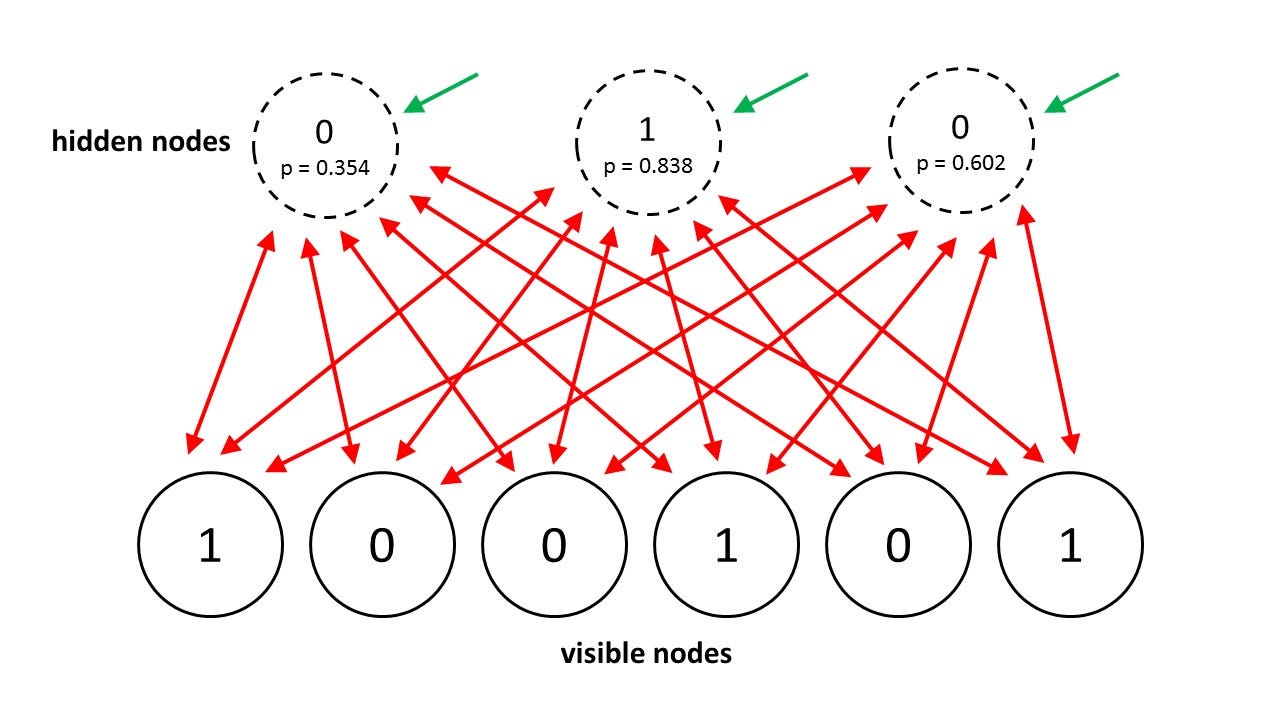
In 2014, Salakhutdinov and Hinton came up with another update for their model, calling it Restricted Boltzmann Machines.
They restrict the connectivity to make inference and learning easier
(only one layer of hidden units and no connections between hidden
units). In an RBM it only takes one step to reach thermal equilibrium
when the visible units are clamped.
Another efficient mini-batch learning procedure for RBM goes like this:
- For the positive phase, first clamp a data vector on the visible units. Then compute the exact value of <ViHj> for all pairs of a visible and a hidden unit. For every connected pair of units, average <ViHj> over all data in the mini-batch.
- For the negative phase, also keep a set of “fantasy particles.” Then update each fantasy particle a few times using alternating parallel updates. For every connected pair of units, average ViHj over all the fantasy particles.
7 — Deep Belief Network
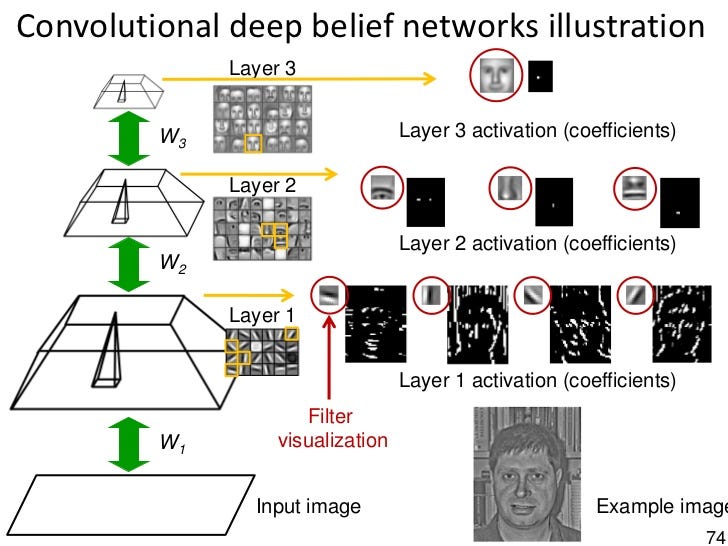
Back-propagation
is considered the standard method in artificial neural networks to
calculate the error contribution of each neuron after a batch of data is
processed. However, there are some major problems using
back-propagation. Firstly, it requires labeled training data; while
almost all data is unlabeled. Secondly, the learning time does not scale
well, which means it is very slow in networks with multiple hidden
layers. Thirdly, it can get stuck in poor local optima, so for deep nets
they are far from optimal.
To
overcome the limitations of back-propagation, researchers have
considered using unsupervised learning approaches. This helps keep the
efficiency and simplicity of using a gradient method for adjusting the
weights, but also use it for modeling the structure of the sensory
input. In particular, they adjust the weights to maximize the
probability that a generative model would have generated the sensory
input. The question is what kind of generative model should we learn?
Can it be an energy-based model like a Boltzmann machine? Or a causal
model made of idealized neurons? Or a hybrid of the two?
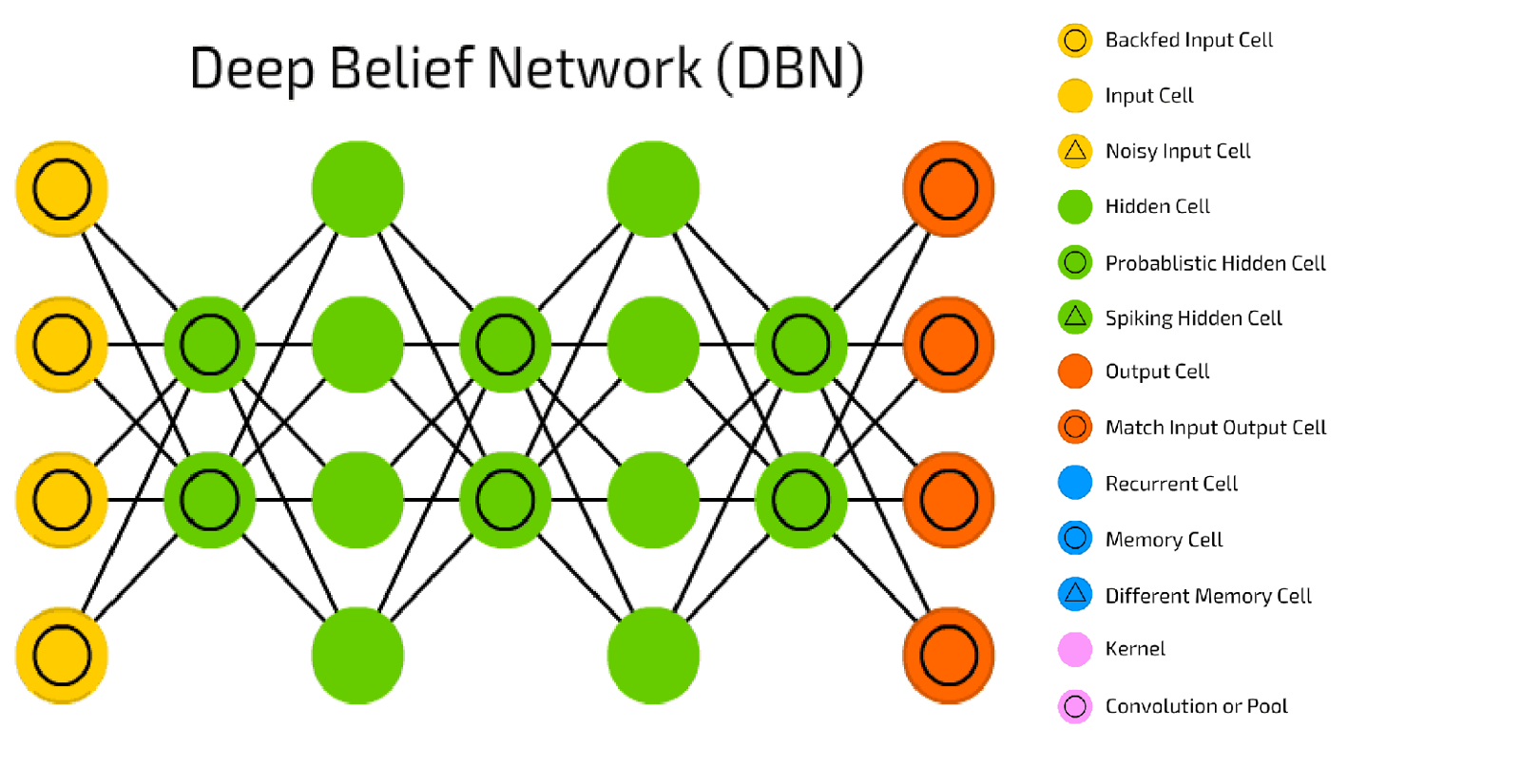
A belief net
is a directed acyclic graph composed of stochastic variables. Using
belief net, we get to observe some of the variables and we would like to
solve 2 problems: 1) The inference problem: Infer the states of the
unobserved variables, and 2) The learning problem: Adjust the
interactions between variables to make the network more likely to
generate the training data.
Early
graphical models used experts to define the graph structure and the
conditional probabilities. By then, the graphs were sparsely connected;
so researchers initially focused on doing correct inference, not on
learning. For neural nets, learning was central and hand-writing the
knowledge was not cool, because knowledge came from learning the
training data. Neural networks did not aim for interpretability or
sparse connectivity to make inference easy. Nevertheless, there are
neural network versions of belief nets.
There are two types of generative neural network composed of stochastic binary neurons: 1) Energy-based, in which we connect binary stochastic neurons using symmetric connections to get a Boltzmann Machine; and 2) Causal,
in which we connect binary stochastic neurons in a directed acyclic
graph to get a Sigmoid Belief Net. The descriptions of these two types
go beyond the scope of this article.
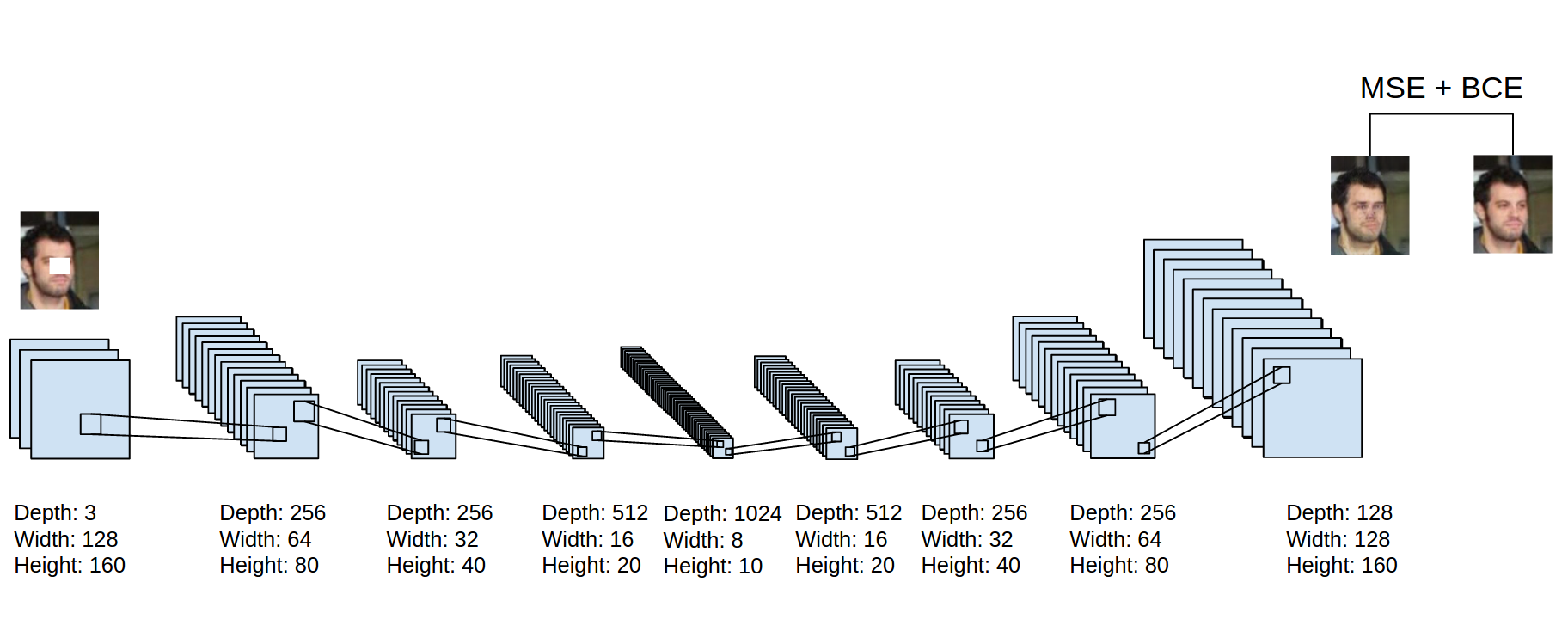
8 — Deep Auto-encoders
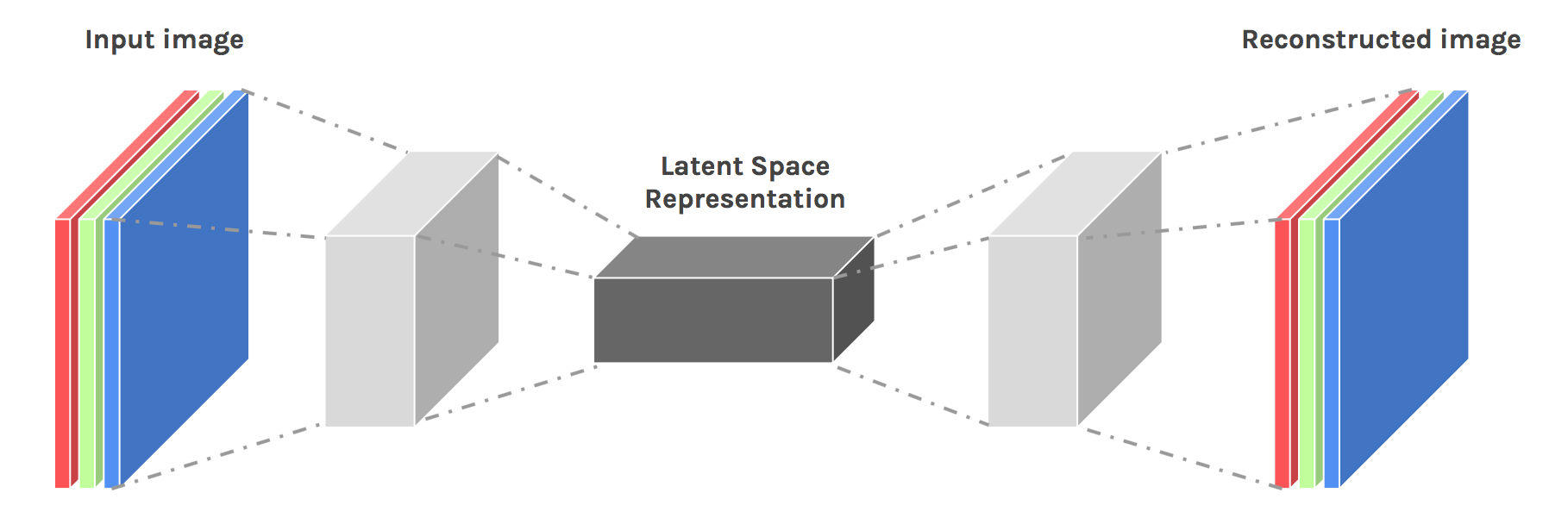
Finally, let’s discuss deep auto-encoders. They
always looked like a really nice way to do non-linear dimensionality
reduction because of a few reasons: They provide flexible mappings both
ways. The learning time is linear (or better) in the number of training
cases. And the final encoding model is fairly compact and fast. However,
it turned out to be very difficult to optimize deep auto encoders using
back propagation. With small initial weights, the back propagated
gradient dies. We now have a much better ways to optimize them; either
use unsupervised layer-by-layer pre-training or just initialize the
weights carefully as in Echo-State Nets.
For pre-training task, there are actually 3 different types of shallow auto-encoders:
- RBM’s as auto-encoders: When we train an RBM with one-step contrastive divergence, it tries to make the reconstructions look like data. It’s like an auto encoder, but it’s strongly regularized by using binary activities in the hidden layer. When trained with maximum likelihood, RBMs are not like auto encoders. We can replace the stack of RBM’s used for pre-training by a stack of shallow auto encoders; however pre-training is not as effective (for subsequent discrimination) if the shallow auto encoders are regularized by penalizing the squared weights.
- Denoising auto encoders: These add noise to the input vector by setting many of its components to 0 (like dropout, but for inputs). They are still required to reconstructing these components so they must extract features that capture correlations between inputs. Pre-training is very effective if we use a stack of denoting auto encoders. It’s as good as or better than pre-training with RBMs. It’s also simpler to evaluate the pre-training because we can easily compute the value of the objective function. It lacks the nice variational bound we get with RBMs, but this is only of theoretical interest.
- Contractive auto encoders: Another way to regularize an auto encoder is to try to make the activities of the hidden units as insensitive as possible to the inputs; but they cannot just ignore the inputs because they must reconstruct them. We achieve this by penalizing the squared gradient of each hidden activity with respect to the inputs. Contractive auto encoders work very well for pre-training. The codes tend to have the property that only a small subset of the hidden units are sensitive to changes in the input.
In
brief, there are now many different ways to do layer-by-layer
pre-training of features. For datasets that do not have huge numbers of
labeled cases, pre-training helps subsequent discriminative learning.
For very large, labeled datasets, initializing the weights used in
supervised learning by using unsupervised pre-training is not necessary,
even for deep nets. Pre-training was the first good way to initialize
the weights for deep nets, but now there are other ways. But if we make
the nets much larger, we will need pre-training again!
Last Takeaway
Neural
networks are one of the most beautiful programming paradigms ever
invented. In the conventional approach to programming, we tell the
computer what to do, breaking big problems up into many small, precisely
defined tasks that the computer can easily perform. By contrast, in a
neural network we don’t tell the computer how to solve our problem.
Instead, it learns from observational data, figuring out its own
solution to the problem at hand.
Today,
deep neural networks and deep learning achieve outstanding performance
on many important problems in computer vision, speech recognition, and
natural language processing. They’re being deployed on a large scale by
companies such as Google, Microsoft, and Facebook.
I
hope that this post helps you learn the core concepts of neural
networks, including modern techniques for deep learning. You can get all
the lecture slides, research papers and programming assignments I have
done for Dr. Hinton’s Coursera course from my GitHub repo here. Good luck studying!
— —